Pre-revenue startup bez działu finansów. Anatomia systemu agentów AI.

Dziś jest 9 maja 2026. Dwa dni temu prowadziłem prelekcję na NoCode Poland #4 - "Jak 2 założycieli robi robotę całego zespołu". Tytuł brzmi jak clickbait, ale tydzień wcześniej, 1 maja, część tego, o czym mówiłem, jeszcze nie istniała.
Pierwszego maja w 200IQ LABS - pre-revenue spółce, którą prowadzę z Przemkiem - nie było działu finansów. Zero raportu zarządczego za kwiecień. Zero kontroli kosztów na poziomie kategorii. Zero spec-a. Trzeciego maja był pierwszy close kwietnia: 30+ reguł klasyfikacji wytrenowanych z zera, raport zarządczy w monthly/2026-04.md, real EBITDA −16 804 PLN udokumentowane z trzema decyzjami korekcyjnymi planu na kolejne miesiące.
Dwa dni od zera do działającego systemu zarządczego. Powiem szczerze - robiłem to częściowo na potrzeby prelekcji. Event Driven Development™ (eventem była ta prelekcja). Ale ten system od dawna miał powstać. Wolę wdrażać PR-y na produkcję niż siedzieć nad numerami - taka prawda founderska. Prelekcja po prostu wymusiła timing.
Ten artykuł nie jest o tym, że "AI zastąpi księgowych". Nie zastąpi - formalna księgowość przez inFakt + księgową robi compliance, i nadal to robi. Ten artykuł jest o tym, jak architektonicznie zbudować system agentów AI, który realnie zastępuje role specjalistów w warstwie zarządczej - w tym, gdzie dział nie istnieje, bo firma jest za mała, żeby zatrudnić, i za duża, żeby improwizować.
Trzy filary, do których wracam w całym tekście:
- Skills automatyzują procesy. Workflow staje się rzeczownikiem - /finances close 2026-04 zamiast 6 manualnych kroków.
- Determinizm przez reguły. Hybryd rules-first + LLM fallback + learning loop. System konwerguje od probabilistycznego do deterministycznego.
- Wspólny kontekst. CLAUDE.md, MEMORY.md, struktura context/. Bez tego subagenty są izolowanymi czatami. Z tym - system, który pamięta firmę.
Architektura: jeden diagram, trzy warstwy
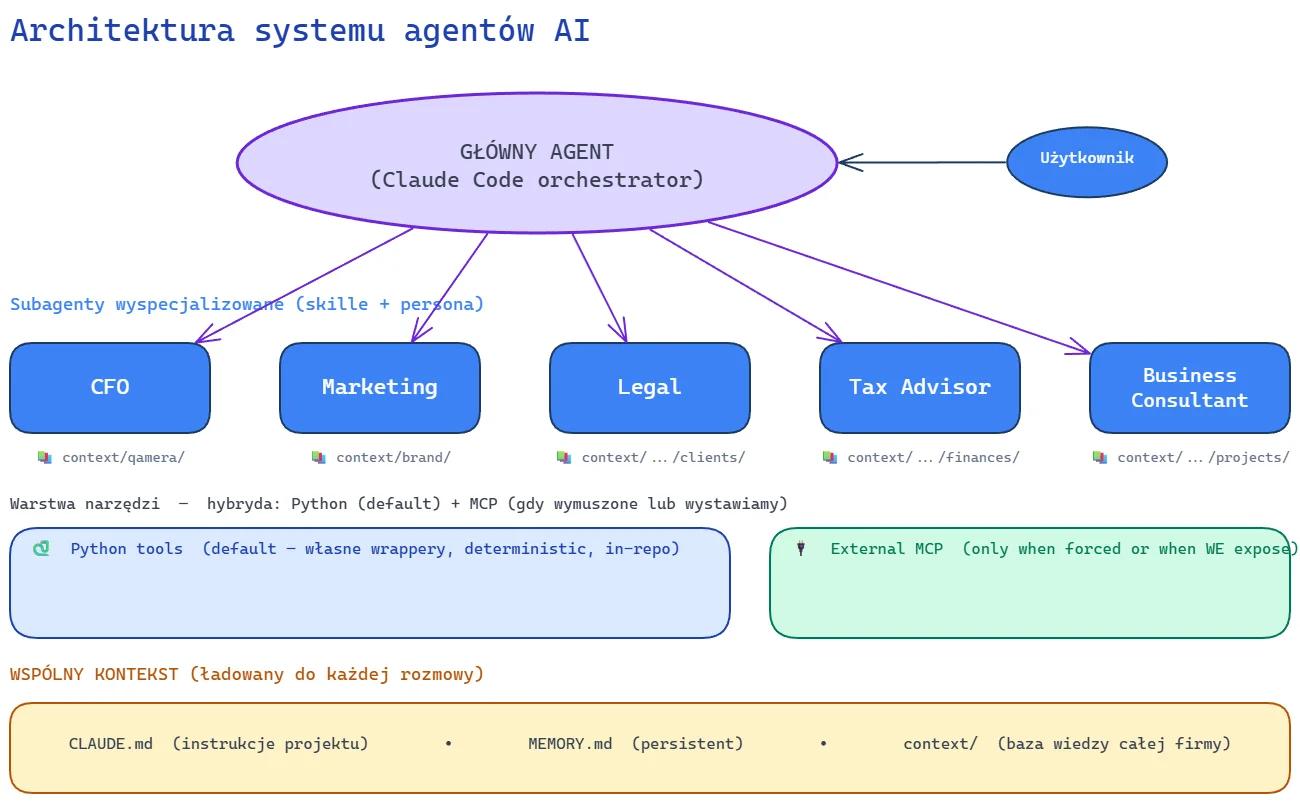
Ten diagram to spine artykułu. Każda z trzech warstw odpowiada jednemu z filarów, do których będę wracał.
Główny agent to Claude Code działający jako orchestrator. Z jego perspektywy ja jestem użytkownikiem, on jest punktem wejścia. Routing do subagentów dzieje się przez skille - wpisuję /finances close 2026-04, agent ładuje skill finances, persona przełącza się na CFO.
Subagenty wyspecjalizowane - CFO, Marketing, Legal, Tax Advisor, Business Consultant - to nie osobne procesy ani osobne modele. To kombinacje skill + persona + scoped context. CFO czyta context/finances/, Marketing czyta context/qamera/ (bo Qamera jest naszym produktem) i context/brand/, Legal czyta context/legal-entities.md i context/company.md. Każda rola widzi tylko to, co jej potrzebne - higiena kontekstu.
Warstwa narzędzi to hybryda Python (default dla zaplanowanego workflow) + External MCP (dla ad-hoc lub gdy API wymusza). Stripe, Revolut, Airtable to Python wrappery w repo - bo wiemy z góry, jak z nich korzystamy. inFakt to MCP, bo endpoint do pobierania kosztów zwraca 403, gdy spółka jest obsługiwana przez biuro księgowe - oficjalny MCP server omija to ograniczenie. Qamera AI ma własne MCP, z którego korzystają zarówno cudzy agenci, jak i my sami - bo do ad-hoc eksploracji własnego produktu MCP jest po prostu szybsze niż pisanie skryptu pod każde nowe zapytanie.
Wspólny kontekst to substrate całego systemu. CLAUDE.md ładuje się na każdą rozmowę - instrukcje projektu, konwencje, ścieżki. MEMORY.md jest persistent między sesjami. context/ to strukturalna baza wiedzy: finanse, klienci, projekty, operacje. Subagenty czytają z tej bazy - i dzięki temu nie są izolowanymi czatami.
Teraz po kolei.
Pillar 1: Skills automatyzują procesy
Skill to jednostka, w której zamykasz proces - trigger, kroki, decyzje, integracje. Przed skillem masz workflow zdefiniowany w głowie i w czyimś notatniku. Z skillem masz workflow jako rzeczownik: /finances close YYYY-MM, /ingest, /slides:new. Komenda zamiast pamięci.
Brzmi banalnie. Nie jest. Bez skilla każdorazowo improwizuję: "hej, zaciągnij dane Stripe za kwiecień, potem Revolut, sklasyfikuj transakcje, sprawdź accruals, zapisz raport". To znaczy 6 razy dziennie wymyślam tę samą sekwencję. Z /finances close 2026-04 - jedna komenda, deterministyczna sekwencja faz.
/finances close - 6 faz
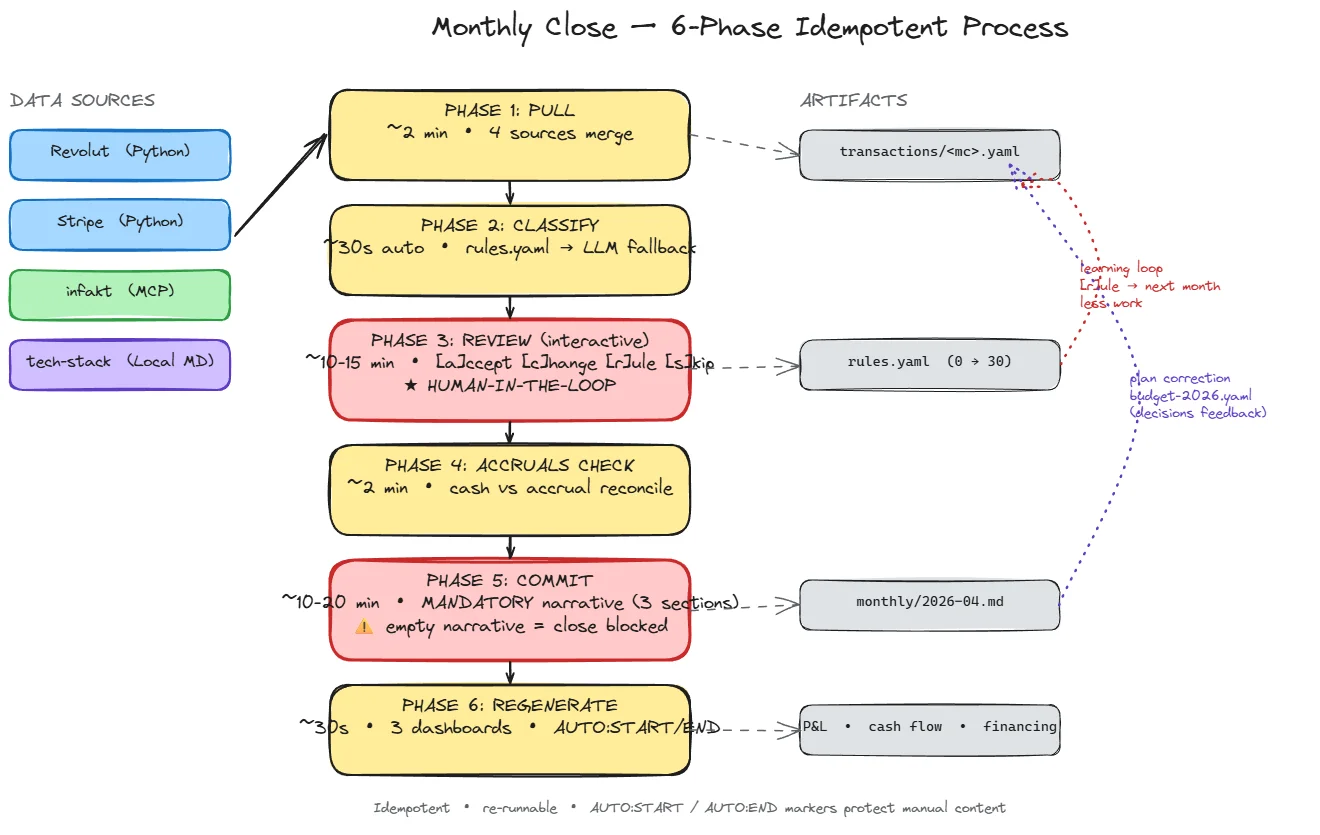
PHASE 1: PULL (~2 min) Revolut + Stripe (Python) + inFakt (MCP) + tech-stack
PHASE 2: CLASSIFY (~30s) rules.yaml deterministic → LLM fallback
PHASE 3: REVIEW (~10-15min interactive) [a/c/r/s] learning loop
PHASE 4: ACCRUALS CHECK (~2 min) accrued-liabilities.yaml matching
PHASE 5: COMMIT (~10-20 min) mandatory narrative blokuje close
PHASE 6: REGENERATE (~30s) 3 dashboards, AUTO:START/END markers
Każda faza jest idempotentna - restart po awarii nie duplikuje danych. Możesz ten close uruchomić, przerwać po PHASE 3, wrócić za godzinę i kontynuować od miejsca przerwania. To nie jest pipe-and-pray; to operacja transakcyjna w sensie "można powtórzyć i nic złego się nie stanie".
Wideo: jeden close na żywo
Pełny close kwietnia 2026 uruchomiony jako /finances close 2026-04. ~7 minut, 6 faz, 2 iteracje QA zostały w nagraniu - meta-przekaz: można korygować rozmową z agentem.
W nagraniu zostały dwie iteracje QA - momenty, w których zatrzymałem agenta, zauważyłem coś, co nie pasowało, i poprosiłem o korektę bez restartowania całej fazy. Świadomie ich nie wyciąłem. To pokazuje rzecz, która ginie w marketingowych demo: workflow z agentem nie jest skryptem jednoprzejściowym. Można korygować rozmową, agent dopasowuje stan, kontynuuje.
Generalizacja: każdy proces może być skillem
/finances close to flagowy skill, ale ta sama mechanika działa wszędzie. /ingest klasyfikuje pliki wrzucone do inbox/ - opisałem to dokładniej w PIT-38 case study. /slides:new generuje szkielet prezentacji. Meta-twist: te slajdy NCP4, o których piszę w intro, powstały tym samym workflow. Sam skill /blog-article-writer używany do tego artykułu ma własne fazy: prime → plan → execute → validate → translate.
Mandatory narrative blokuje close
PHASE 5 wymaga, żeby człowiek napisał trzy sekcje narracji w monthly/<YYYY-MM>.md:
- Co się działo niespodziewanego (vs plan).
- Decyzje podjęte w trakcie miesiąca.
- Plan na następny miesiąc / korekta planu.
Pusty narrative blokuje close. System nie zamknie miesiąca dopóki nie wpiszesz czegoś w każdą sekcję.
To wygląda jak zbędny formalizm - i z perspektywy "chcę szybko zamknąć" tak jest. Ale z perspektywy "za pół roku patrzę na variance EBITDA −3160 vs plan i nie wiem dlaczego" - to jedyny sposób, żeby decyzje miały trwałą pamięć.
Refleksja jest częścią procesu, nie opcją.
To pattern szerszy niż finanse: za każdym razem, gdy automatyzujesz coś, w czym wartość leży w rozumieniu a nie w wykonaniu - dodaj human-in-the-loop checkpoint, który nie da się ominąć. Inaczej zautomatyzujesz wykonanie i zniszczysz rozumienie.
Pillar 2: Determinizm przez reguły
Klasyfikacja transakcji jest klasycznym problemem cold-start. Pure rules: każdy nowy vendor wymaga manual setup, miesiąc bez nowych vendorów to dobry tydzień, miesiąc z 5 nowymi to wieczór. Pure LLM: niedeterministyczny, niedrogi w skali, ale niedopuszczalny w finansach - audyt, regulator, przyszła kontrola.
Trzecia droga to hybryd: rules-first + LLM fallback + learning loop.
Rules-first
# rules.yaml - fragment
- id: gworkspace-via-gcp
pattern:
memo: "GCPLD"
source: infakt
amount_range: [200, 500]
classify:
category: opex/saas
unit: null
note: "Google Workspace billowane przez Google Cloud Poland (300-330 PLN/mc)"
created_at: 2026-05-04
- id: gcp-infakt
pattern:
memo: "GCPLD"
source: infakt
amount_range: [500, 999999]
classify:
category: cogs/ai-generation
unit: qamera
note: "Faktury GCP w inFakt z prefiksem GCPLD i kwotą >500 PLN = compute"
created_at: 2026-05-04
Najmocniejszy detal: dwie reguły dla tego samego vendora (GCPLD w inFakt), różniące się tylko amount_range. 200-500 PLN → Google Workspace (kategoria opex/saas). >500 PLN → compute GCP dla pipeline'u Qamery (kategoria cogs/ai-generation).
To jest typ niuansu, który LLM zgaduje zawsze inaczej. Jednego dnia zaklasyfikuje cały GCPLD jako Workspace, drugiego jako compute, trzeciego rozdzieli losowo. Tu mamy odpowiedź zaszytą jako kod. Audytowalne, deterministyczne, idempotentne.
Pole note: jest równie ważne jak sam pattern. Bez tej notki za pół roku patrząc na regułę nie wiem, dlaczego rozdzielenie po amount_range ma sens. Reguła bez note-a to długofalowy debt.
LLM fallback z few-shot examples
Gdy żadna reguła nie matchuje, agent leci do LLM z few-shot promptem. Każdy example w examples.yaml ma konkretny reasoning:
# examples.yaml - fragment
- transaction:
date: 2026-04-10
amount: -127.40
memo: "BYTEPLUS API USAGE PAY-AS-YOU-GO"
source: revolut
classification:
category: cogs/ai-generation
unit: qamera
reasoning: "Byteplus to provider Kling AI używany do generacji video w produkcie"
LLM dostaje 15-25 takich przykładów per kategoria. Zwraca klasyfikację plus własne reasoning. reasoning widoczny dla użytkownika w fazie REVIEW - to nie black box. Widzę nie tylko "kategoria X", ale dlaczego.
Learning loop: REVIEW [a]ccept / [c]hange / [r]ule / [s]kip
Pętla per LLM-classified transakcja. Cztery decyzje:
| Opcja | Co robi |
|---|---|
| [a]ccept | LLM zgadł, ale to jednorazowy przypadek |
| [c]hange | LLM się pomylił, ręczna korekta |
| [r]ule | Akceptuje + tworzy regułę dla podobnych |
| [s]kip | Nie wiem, wracamy w następnym close |
Złota zasada: jeśli transakcja prawdopodobnie się powtórzy → [r]ule. 30 sekund teraz, oszczędzasz minuty przez kolejne miesiące. Każde [r]ule zamraża LLM-owe zgadywanie w deterministycznej regule w rules.yaml. Następny close - ta sama transakcja wpada w "auto-classified" deterministycznie.
Real number: pierwszy close (kwiecień 2026) wytworzył 30+ reguł z zera. Trzy typy patternów ujawniły się natychmiast:
- Po memo - czyste pattern matching. Byteplus, Cursor, Meta Pay.
- Po prefiksie faktury inFakt + kwocie - GCPLD z amount_range: [200, 500] to Workspace, z [500, ∞] to compute. Ten sam vendor, dwie kategorie.
- Po reseller pattern - Paddle 24 EUR ≈ 100 PLN to n8n cloud. Ale Paddle z inną kwotą = REVIEW (może być inny produkt sprzedawany przez Paddle).
System konwerguje od probabilistycznego do deterministycznego. To rzadki design - większość narzędzi do kategoryzacji budżetu jest albo w 100% deterministyczna (sztywne reguły, dużo manuala), albo w 100% probabilistyczna (LLM/ML, brak audytu). Hybryd z [r]ule jako pomostem między obiema stronami daje cold-start LLM-a i długoterminowy audit deterministycznych reguł.
Idempotent regeneration jako ortogonalny mechanizm determinizmu
Drugą warstwą determinizmu są dashboardy. PHASE 6 regeneruje 3 pliki: _dashboard.md, _alerts.md, _runway.md. Pytanie: co z ręcznymi notatkami, które dopisałem w trakcie miesiąca? Jeśli regeneracja nadpisuje cały plik - moje notatki znikają i przestaję pisać notatki.
Rozwiązanie: markery zasięgu.
# 200IQ LABS - Finances Dashboard
<!-- AUTO:START -->
## Cash position & runway
| Metryka | Wartość |
|---|---|
| Cumulative shareholder loans | 74 300 PLN |
| Confirmed financing (czerwiec) | +100 000 PLN |
| Accrued liabilities (UoD payout maj) | −24 000 PLN |
| Run-rate burn | ~14-14.5k PLN/mc |
<!-- AUTO:END -->
## Notatki ręczne (poza markerami - przetrwają regenerację)
- 2026-05-04: pierwszy close systemu. Manual regeneracja dashboardów.
- Plan finalize: nie wykonano - tryb `draft` świadomie do kolejnego close.
Markery AUTO:START / AUTO:END ograniczają zasięg regeneracji. Wszystko poza markerami przeżywa każdą regenerację. Bez tego nikt nie pisze ręcznych notatek w auto-generowanych dokumentach - i te dokumenty stają się martwe. Ten prosty pattern decyduje o tym, czy dashboardy są używane, czy ignorowane.
Pillar 3: Wspólny kontekst (substrate)
Trzeci filar to warstwa, która sprawia, że wszystkie subagenty są spójne. Bez wspólnego kontekstu CFO i Marketing nie wiedzą o sobie nawzajem - masz 5 izolowanych czatów, każdy ze swoją wersją prawdy. Z wspólnym kontekstem masz system, który pamięta firmę.
Trzy warstwy wspólnego kontekstu
- CLAUDE.md (per-projekt) - instrukcje, konwencje, ścieżki, "co agent ma robić, jak nie wie". Ładuje się na każdą rozmowę.
- MEMORY.md (cross-conversation) - auto-memory, persistent między sesjami. Tu siedzi "użytkownik woli krótkie podsumowania", "projekt X używa OpenSpec", "data dziś to YYYY-MM-DD".
- context/ (knowledge base) - strukturalna baza per dziedzina. context/finances/, context/qamera/, context/clients/, context/operations/.
Struktura katalogów (uproszczona):
agentic-ai-system/
├── CLAUDE.md # instrukcje projektu
├── memory/
│ └── MEMORY.md # auto-memory, persistent
├── context/
│ ├── finances/ # ← czyta skill CFO
│ ├── qamera/ # ← czyta skill Marketing (revenue + brand)
│ ├── clients/ # ← czyta skill Business Consultant
│ └── operations/
├── skills/
│ ├── finances/SKILL.md
│ ├── ingest/SKILL.md
│ └── slides/SKILL.md
└── tools/
├── stripe/ # Python wrappers
├── revolut/ # Python wrappers
└── airtable/ # Python wrappers
Każdy subagent ma scope - nie czyta wszystkiego. CFO sięga do context/finances/ i context/operations/, dla revenue ma read-only dostęp do context/qamera/. Nie czyta context/clients/ (to zasięg Business Consultanta), bo nie potrzebuje. Higiena kontekstu to drugi multiplikator wartości - bez niej każde pytanie do CFO zaciąga połowę firmy do tokenów.
Python tools (default) vs External MCP (when forced)
Reguła: Python skrypt dla zaplanowanego workflow. MCP dla ad-hoc lub gdy API wymusza.
| Integracja | Podejście | Dlaczego |
|---|---|---|
| Stripe (subskrypcje Qamery) | Python | Wiemy z góry, czego potrzebujemy - wrapper to część specyfikacji |
| Revolut (transakcje firmowe) | Python | Stała sekwencja w /finances close, własny wrapper |
| Airtable (CRM) | Python | Powtarzalne operacje na CRM, własny wrapper |
| inFakt (księgowość) | MCP | Endpoint kosztów zwraca 403, gdy spółkę obsługuje biuro księgowe - MCP wymuszone |
| Qamera AI (nasz produkt) | MCP | I my, i cudzy agenci. REST API też dostępne, ale do ad-hoc eksploracji MCP jest po prostu szybszy do podpięcia |
Dlaczego Python > MCP, gdy workflow jest planowany:
- Oszczędność tokenów. MCP ładuje opisy narzędzi do kontekstu każdej rozmowy. Skrypt = zero overhead. Skrypt jest wywołany tylko wtedy, gdy agent zdecyduje, że go potrzebuje.
- Determinizm. Skrypt robi dokładnie to, co napisano. Bez "model zinterpretował narzędzie inaczej w innej rozmowie".
- Trywialne tworzenie. "Agent, potrzebuję skrypt, który wyciągnie z Stripe wszystkie subskrypcje aktywne na dzień X" → agent generuje, ja code-review, commit. 15 minut.
- Pełna kontrola. Kod w repo, w wersji, czytelny dla innego dewelopera. Mogę debugować Pythonem, dodać logging, zmienić output format - bez negocjacji z protokołem MCP.
Dlaczego MCP, gdy używamy ad-hoc:
Jeśli dopiero odkrywam, jak będę z czegoś korzystać - pisanie skryptu jest przedwczesne. Nie wiem jeszcze, jakie pola mnie interesują, jakie filtry, jaki output format. MCP daje agentowi natychmiastowy dostęp do API; po kilku iteracjach widzę pattern, który warto utrwalić - i wtedy piszę skrypt. Skrypt jest częścią specyfikacji workflow; MCP jest narzędziem do eksploracji.
Z Qamerą tak właśnie korzystamy: cudzy agenci uderzają w MCP, my też - gdy chcemy szybko sprawdzić coś we własnym produkcie. Gdybyśmy mieli stały workflow w stylu "co tydzień generuj X dla klienta Y" - pisalibyśmy skrypt. Na razie nie mamy, więc MCP wystarcza.
Z inFaktem nie mamy wyboru - REST API zwraca 403 na endpoint kosztów, gdy spółkę obsługuje biuro księgowe. MCP tu nie jest wyborem architektonicznym, tylko jedyną dostępną drogą do danych.
Subagenty czytają tylko swój scope
Wracając do pierwszego diagramu: każdy subagent (skill + persona) ma scope w swojej linii kontekstu. Skill finances ma front-matter, który jawnie deklaruje:
context_scope:
- context/finances/
- context/operations/
- context/qamera/ # read-only, dla revenue z subskrypcji
Bez tego ograniczenia agent pyta "jakie były transakcje w marcu" i ładuje kontekst całej firmy do tokenów. Z ograniczeniem - ładuje tylko context/finances/transactions/2026-03.yaml plus reguły. Mniej tokenów, szybsza odpowiedź, mniejsze ryzyko halucynacji.
Pisałem o tym samym wzorcu w innym kontekście - separacja inbox/ / archive/ / data/ w PIT-38 case study. Wzorzec się generalizuje: agent pracuje na czystych, przetworzonych plikach, nie na surowiznie.
Case study: real numbers z kwietnia 2026
Dowód, że to nie demo. Pierwszy close, wykonany 2026-05-04, wygenerował:
| Linia | Actual | Plan | Δ |
|---|---|---|---|
| Revenue | 347 PLN | 598 PLN | −42% |
| Costs | 17 151 PLN | 14 242 PLN | +20% |
| EBITDA | −16 804 PLN | −13 644 PLN | −23% |
| cogs/ai-generation | 1 709 | 700 | +144% 🔴 |
| opex/marketing | 2 996 | 1 500 | +100% 🔴 |
| opex/saas | 2 112 | 1 633 | +29% 🟡 |
Trzy decyzje wynikające z close-a (zapisane w monthly/2026-04.md):
- GCP +144% vs plan → plan był błędny (700 PLN), realny run-rate 1000-1600 PLN/mc historycznie. Plan May-Dec podniesiony retroaktywnie do 1500-1800 PLN. Świadoma decyzja NIE optymalizować GCP - część tego to content marketingowy (own + materiały dla klientów). Klasyfikacja "to faktycznie marketing" nie zmienia kategorii (GCP zostaje w cogs/ai-generation), ale uzasadnia wyższy plan.
- Cursor billowany 4×/mc (716 PLN vs plan 217) → planowana migracja Cursor → Claude (sztywny ~90 EUR/mc cap, predictable koszt zamiast usage-based).
- Meta Ads off od maja - strategia była błędna, kierunek do dopracowania. Plan kontroli: w close maja sprawdzimy, że spend < 300 PLN.
Pointa: decyzje wynikają z systemu, ale nie podejmuje ich system. System pokazuje variance i wymaga w PHASE 5 narrative. Decyzję podejmuję ja - ale mam ją udokumentowaną na wypadek, gdy za pół roku zapomnę dlaczego.
Plan break-even: wrzesień 2026 (revenue 12 184 vs costs 12 842, EBITDA −658). Plan agresywny - wymaga walidacji w kolejnych close-ach. Plan = żywy dokument, korygowany po każdym close gdy run-rate się zmienia. Drift > 30% = wymaga rewizji.
Czego nie polecam
Mapy ryzyk, mirror sekcji z PIT-38 case study.
- Nie polecam tego setupu osobie bez programistycznego komfortu. Markdown, YAML, git, terminal, edycja convention files - wymaga rozumienia narzędzi. Bez tego strata czasu na setup zje wszystkie zyski. Bezpieczniejsza ścieżka: gotowy SaaS do controllingu (Causal, Runway, Pry) + Excel + księgowa.
- Manual first, automate after pain. Pierwsze 2-3 close-y MUSZĄ być manualne. Bez ręcznego wykonania połowa reguł byłaby zaprojektowana źle. Pierwszy close ujawnił 30+ patternów do zakodowania - w tym nieoczywiste (np. że GCPLD to dwie kategorie, nie jedna). Skrypty piszesz po, nie przed.
- System zarządczy ≠ księgowość formalna. inFakt + księgowa robią compliance. Ten system robi decyzje. Nie podmieniaj jednego za drugie - uzupełniają się, nie zastępują. Ja nadal płacę księgowej comiesięczny ryczałt; ten system nie usuwa tej linii z budżetu.
- LLM-y robią błędy arytmetyczne. Sumowanie do silnika obliczeniowego (Excel, kalkulator, system MF). LLM ma wartość w strukturze i interpretacji, nie w arytmetyce. Pisałem o tym w PIT-38 case study - zostawiłem 6 groszy na stole, bo LLM pomylił się przy odejmowaniu dwóch sześciocyfrowych liczb.
- Nie skaluje się liniowo poza 1 firmę. System zaprojektowany dla 200IQ LABS. Wzorce się generalizują (skills, rules, kontekst); konkretne YAML-e nie. "Nie kopiujcie setupu, wyciągajcie zasady" - to było motto talku NCP4 i jest motto tego artykułu.
Kluczowe wnioski
- Skills sprawiają, że proces staje się rzeczownikiem. /finances close YYYY-MM zamiast 6 manualnych kroków. Każdy powtarzalny workflow zasługuje na własny skill - z fazami, z idempotency, z mandatory checkpoints tam, gdzie wartość leży w rozumieniu.
- Determinizm budujesz iteracyjnie. Rules-first + LLM fallback + opcja [r]ule w REVIEW = system konwerguje z probabilistycznego do deterministycznego. Po pierwszym close mieliśmy 30+ reguł. Po dziesiątym będziemy mieli ~150, LLM wywoływany sporadycznie.
- Wspólny kontekst (CLAUDE.md, MEMORY.md, context/) to substrate, nie ozdoba. Bez niego subagenty są izolowanymi czatami. Z nim - system, który pamięta firmę i dzieli wiedzę między rolami.
- Python skrypt dla zaplanowanego workflow, MCP dla ad-hoc. Skrypt jest częścią specyfikacji - token-efficient, deterministic, code-reviewable. MCP daje natychmiastowy dostęp gdy nie wiesz jeszcze, jak będziesz korzystać, lub gdy API wymusza.
- Refleksja jest częścią procesu, nie opcją. Mandatory narrative blokuje close. Bez tego za pół roku nie wiesz dlaczego coś było.
Wolę wdrażać kod niż liczyć - i agenty pomagają mi w obu. Ten system od dawna miał powstać. Eventem napędzającym była prelekcja. Działa.
Prowadzisz pre-revenue startup i myślisz o systemie zarządczym AI?
Pomagam founderom i konsultantom technologicznym projektować architekturę agentów AI dla operacji firmy - skills, deterministyczne reguły, wspólny kontekst. Pokażę, jak taki setup mógłby wyglądać u Ciebie.
Umów bezpłatną konsultacjęPrzydatne zasoby
- Claude Code - dokumentacja - referencja do skills, settings, MCP, hooks
- Model Context Protocol - spec - czym jest MCP i kiedy ma sens
- PIT-38 case study - ten sam wzorzec architektoniczny w kontekście rozliczeń podatkowych
- Skills 2.0 - multi-agent system do zarządzania firmą - szerszy kontekst Skills 2.0 i rola subagentów
- OpenSpec workflow - strukturyzowana praca z AI - spec-driven development jako fundament pod skille
- Spec-driven SEO na portfolio i Qamera AI - inny case study, ten sam typ workflow
FAQ
Czy ten wzorzec (skills + rules + wspólny kontekst) działa tylko w Claude Code, czy w innych agentach też?
Wzorzec jest agent-agnostic. Skills mapują się na komendy/funkcje w innych systemach (Cursor commands, n8n workflows, custom CLI). Rules + few-shot examples to standardowa technika ML. Wspólny kontekst (markdown + struktura katalogów) działa wszędzie, gdzie agent ma dostęp do plików. Konkretne mechanizmy (CLAUDE.md, MCP, MEMORY.md) są specyficzne dla Anthropic, ale zasady architektoniczne się generalizują na każdy LLM-driven system.
Ile czasu zajmuje zbudowanie takiego systemu od zera?
Pierwszy działający close - z OpenSpec, schemami YAML i 30+ regułami - zajął nam dwa dni intensywnej pracy w dwie osoby. Pełna stabilizacja (auto-pull skrypty, scheduled close, integracja z formalną księgowością) zakłada się na 4-6 tygodni przy regularnej miesięcznej kadencji. Każdy dzień, w którym używasz manualnie zaprojektowanego skilla, jest dniem produktywnym - nie czekasz, aż system będzie kompletny, bo wartość pojawia się natychmiast po pierwszym close-u.
Dlaczego Python skrypt zamiast MCP, jeśli MCP jest standardem?
MCP ładuje opisy narzędzi do kontekstu każdej rozmowy - to koszt tokenów i potencjalna niejednoznaczność interpretacji w różnych sesjach. Python skrypt to zero overhead, deterministyczny output, kod w repo do code-review. Skrypt piszemy dla zaplanowanego workflow (Stripe, Revolut, Airtable - wiemy z góry, czego potrzebujemy, więc skrypt jest częścią specyfikacji). MCP używamy dla ad-hoc (eksploracja własnej Qamery, gdy nie wiemy jeszcze jakie zapytania będą się powtarzać) lub gdy API wymusza (inFakt zwraca 403 na endpoint kosztów, gdy spółkę obsługuje biuro księgowe). Pattern: po kilku iteracjach ad-hoc widać, co warto utrwalić w skrypcie.
Czy LLM nie pomyli się przy klasyfikacji finansowej? Co z audytem dla regulatora?
Hybryd (rules-first + LLM fallback) projektujemy specjalnie po to, żeby zminimalizować LLM-classified transakcje. Każda LLM-classified transakcja przechodzi przez REVIEW - człowiek widzi reasoning i decyduje [a]ccept/[c]hange/[r]ule/[s]kip. Po pierwszym close mieliśmy 30+ reguł, które deterministycznie wyłapują 80%+ kolejnych transakcji. Audit trail leży w rules.yaml plus monthly/<YYYY-MM>.md - każda decyzja udokumentowana, każda reguła ma note: z uzasadnieniem. Formalna księgowość (compliance) idzie nadal przez inFakt + księgową; ten system jest zarządczy, nie compliance.
Co robi mandatory narrative, jeśli mam awaryjny close i nie zdążę napisać 3 sekcji?
Trzy sekcje (niespodzianki / decyzje / plan korekta) blokują close-a do momentu wypełnienia - to świadoma decyzja. W skrajnym przypadku możesz wpisać do każdej sekcji jedno zdanie ("brak niespodzianek vs plan", "brak decyzji", "kontynuujemy bez korekt"). System nie ocenia jakości narrative, tylko jego obecność. Punkt jest taki, że za pół roku patrząc na variance EBITDA potrzebujesz dowolnego kontekstu - lepiej krótkiego niż żadnego. Ten formalizm jest celowy.
Czy ten system działa dla firmy na revenue, nie tylko pre-revenue?
Tak, wzorzec się skaluje - kategorie P&L i caps trzeba dopasować, mandatory narrative staje się jeszcze ważniejszy (więcej transakcji = więcej decyzji do udokumentowania), learning loop daje większy ROI (więcej powtarzalnych vendorów). Ale w post-revenue spółce z dużym wolumenem prawdopodobnie potrzebujesz pełnoprawnego ERP - system zarządczy z markdownem i YAML-em ma sufit przy ~setkach transakcji/miesiąc i kilku osobach decyzyjnych. Nasz scope: pre-revenue → early-revenue, 1-5 osób w firmie. Powyżej tego skali architektura wymaga twardszych narzędzi.