Software 3.0: why your app shouldn't exist

The man who coined the term vibe coding said he'd "never felt more behind as a programmer." That's Andrej Karpathy - OpenAI co-founder, former head of AI at Tesla. In December, agentic models crossed a threshold for him: chunks of code "just came out fine," so he stopped correcting them and started trusting the system.
This isn't a story about writing code faster. It's a story about programming turning into prompting - and if you read "software" as every digital business, it means your product is being rebuilt to be AI-first, whether you like it or not.
For the last few months I've been building with agents every day - the entire portfolio you're reading this on, plus systems in two companies. The more I work with them, the more clearly I see this isn't "just another AI hype cycle." It's a change in the map: abstraction rises, and with it shifts what the human actually does. This article is an attempt to draw that map - so you know which paradigm you operate in, where your moat is, and what can't be delegated.
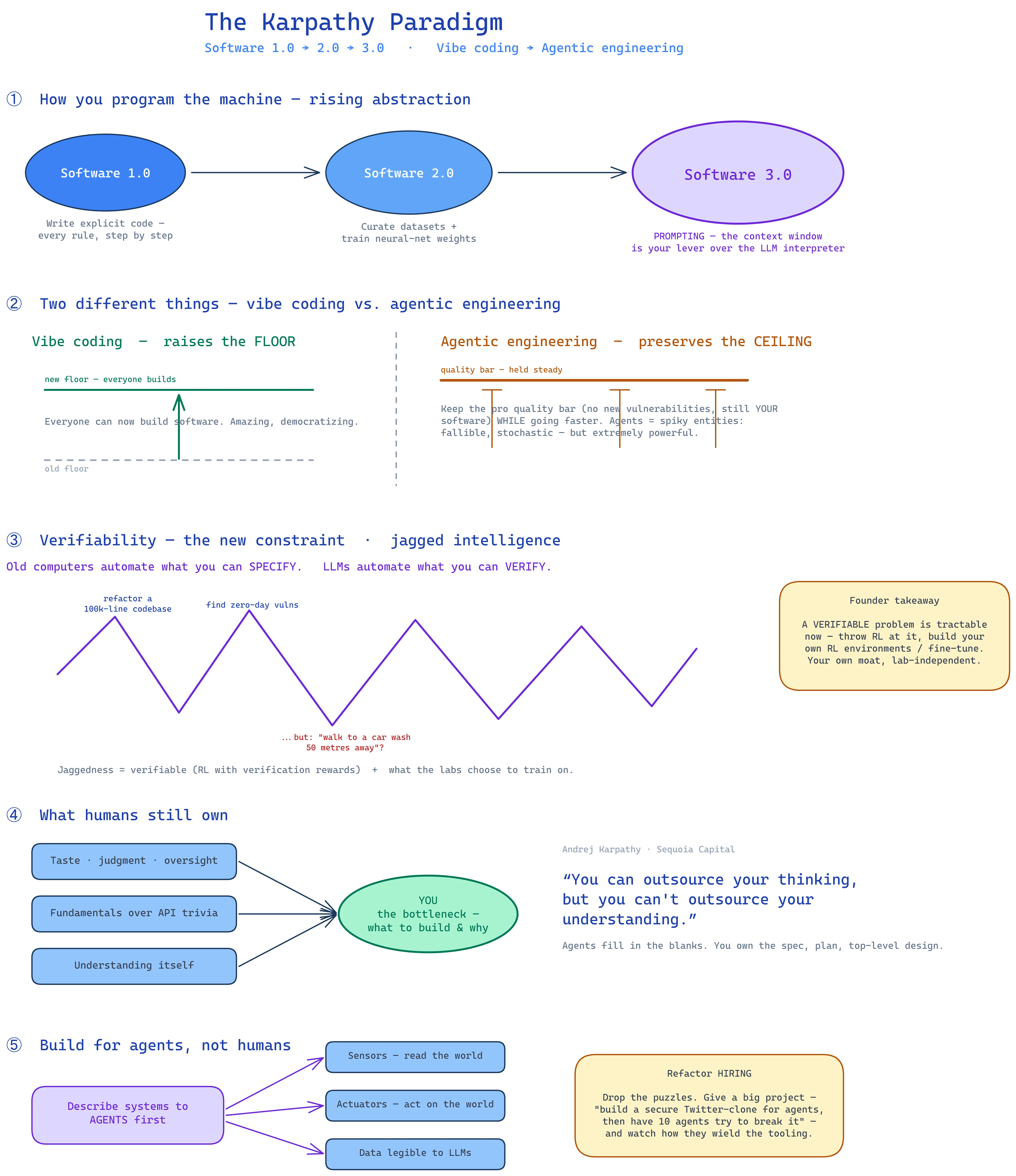
This diagram is the spine of the whole text - I return to each of the five bands in the sections that follow.
Three paradigms: how you "program" the machine
Karpathy arranges the evolution of software into three paradigms - and the key is how you pass your intent to the machine.
- Software 1.0 - you write explicit code, rule by rule. Step one, step two, step three. Brittle, not self-healing: the moment something falls outside the script, it breaks.
- Software 2.0 - you "program" through data. You don't write rules; you curate datasets and train neural-network weights. The logic lives in the weights, not in if statements.
- Software 3.0 - prompting. The context window is your lever over the interpreter that is the LLM.
"Software 3.0 is kind of about your programming now turns to prompting. And what's in the context window is your lever over the interpreter that is the LLM." - Andrej Karpathy
And here comes the reframe that turns this from "a curiosity for programmers" into something that concerns everyone who builds a product. Read "software" as every digital business. The LLM is the engine - and you design the car around it.
"All businesses are literally being restructured to be AI first... AI in the middle being the engine and driving them forward. But that is all the engine is. You get to design your own car."
This isn't abstract. You see the same thing in how companies are starting to operate as agentic systems - with context as the durable asset and software as a layer you regenerate whenever a better model lands.
Four examples that make it concrete
The paradigm sounds abstract until you see what it does to specific business models. Karpathy gives four examples, and each is a different type of product that's shifting right now.
- The installer. Instead of a ballooning script ("step one: accept the terms, step two: find the folder..."), you summon an agent with one command. It owns the goal ("get this installed") and loops through problems it has never seen before. It's a small, self-healing "skill" - a blob of text you paste to your agent.
- The app (MenuGen). Karpathy built a 2.0 app: you photograph a menu, it renders images of the dishes. It became "instantly useless" - because you can just hand the photo to Gemini and say "overlay the items using Nano Banana." Nothing to install. "That app shouldn't exist." And the same is coming for almost every single app.
- The course / specialized knowledge. From sequential Udemy lectures, through a course reshaped by engagement data, to a coach-agent that does it with you while you take action. Not "ask me a question," but "build it with me."
- The service (video editing). From manual Premiere Pro, through Descript trimming the silences, to a text box: "edit this in a viral MrBeast style, under 8 minutes" - and a finished render in minutes.
The common denominator is brutally simple: Software 3.0 sells the outcome, not the tool. If your product is a tool that performs a step rather than delivering a result - it's in the crosshairs.
Vibe coding raises the floor. Agentic engineering preserves the ceiling.
This is, in my view, the most important new distinction in the whole interview - and the place most people get it wrong. Vibe coding and agentic engineering are two different things.
Vibe coding raises the FLOOR. Anyone can now build software. It's democratizing and genuinely great - I described the whole approach in my vibe coding guide. The floor rises for everyone.
Agentic engineering preserves the CEILING. It's a real engineering discipline: keep the professional quality bar - no new vulnerabilities, it's still your software, you're responsible for it - while going faster. Agents are "spiky entities": fallible, a little stochastic, but extremely powerful. The craft is coordinating them without dropping the bar.
"Vibe coding is about raising the floor for everyone... agentic engineering is about preserving the quality bar of what existed before in professional software."
And here's the other side of the coin. The ceiling is very high. The old "10× engineer" is now magnified far beyond 10× - for people who are good at this. It's not a zero-sum game between "AI" and "the human." It's a lever that widens the gap between someone who can direct agents and someone who just clicks "accept."
Verifiability - the new constraint
Where do these models' strengths and weaknesses come from? Karpathy gives one of the best explanations I've heard, and it comes down to a single word: verifiability.
"The previous generation of computers automated what you could specify. This generation automates what you can verify."
Frontier models are trained in giant RL (reinforcement learning) environments with verification rewards. That's why their capabilities are jagged: peaks where the result can be verified (code, math), valleys elsewhere. Jaggedness = what's verifiable, plus what the labs happen to choose to train on.
"How is it possible that a state-of-the-art model will refactor a 100,000-line codebase or find zero-day vulnerabilities, and yet tell me to walk to a car wash 50 metres away?"
For a founder, there's a concrete takeaway. A verifiable problem is tractable today - you can throw RL at it, build your own RL environments, or fine-tune. That's your moat, independent of what the big labs happen to prioritize. If you can cheaply and automatically check whether the output is good, you have leverage that competitors without that verification don't.
What you can't outsource
This is the emotional core of the whole thesis. If an agent can refactor 100,000 lines, what actually remains on the human side?
What remains is taste, judgment, and oversight. You hold the spec, the plan, and the top-level design - the agent "fills in the blanks." What also remains is fundamentals over API trivia. Karpathy no longer remembers whether it's keepdim or axis, reshape or permute - the "intern" has perfect recall for that. But you still have to understand what's happening underneath (e.g. how tensor views and storage work) so you're not silently copying memory in the wrong place.
And at the very bottom there's one thing you'll never hand off:
"You can outsource your thinking, but you can't outsource your understanding."
Karpathy says outright that he now feels like the bottleneck - he's the one who knows what to build and why, and he's the one directing the agents. An anecdote about unreliability illustrates it well: the MenuGen agent tried to match users by cross-correlating email addresses from Stripe and Google instead of using a persistent user ID. It's a "why would you ever do that" mistake - the kind a human has to catch, because the agent lacks the judgment to notice it makes no sense.
I see the same thing in my own work: the agent speeds everything up, but I'm the reviewer who decides what's correct. Building your own knowledge base that an agent maintains is exactly an investment in understanding - I described that process in my piece on a Karpathy-style knowledge base.
Build for agents, not for humans
If agents are becoming the primary "user" of your systems, the logical consequence is that you have to start designing for them. Karpathy has a pet peeve about this: documentation is still written for humans. "Why are people still telling me what to do? What is the thing I should copy-paste to my agent?"
The direction is this:
- Describe systems to agents first.
- Decompose work into sensors (read the world) and actuators (act on the world).
- Keep data structures legible - readable for the LLM.
Ultimately we're heading toward a world where "my agent talks to your agent" - to arrange a meeting, say. And if so, even hiring needs to be refactored. Instead of algorithmic puzzles, you give a candidate a big project - e.g. "build a secure Twitter-clone for agents, then have 10 agents try to break it" - and watch how they wield the tooling. Because wielding tools, not reciting from memory, is the real competency now.
Not animals, but ghosts
Finally, a metaphor that organizes the whole mindset. Karpathy says we're not building animals - we're summoning ghosts.
"We're not building animals. We are summoning ghosts."
These are statistical simulation circuits - a pre-training substrate with RL bolted on - not intelligences shaped by curiosity and evolution. Yelling at them does nothing. The value of the metaphor is practical: it's a mindset. Be appropriately suspicious and check empirically what works, instead of assuming the model "understands" the way a human does.
And here I come back to you. Which paradigm is your product in - 1.0, 2.0, or 3.0? And when the big LLMs can do your task directly, what will remain your moat? Karpathy leaves four answers:
- Data - proprietary datasets, your own RL environments, a model trained on your knowledge and style.
- Prompts and context - the context systems and knowledge base you've built to steer the engine.
- System design - sensors, actuators, UX, and verification loops around the model. The engine is just the engine; you design the car.
- Trust - brand and accountability for the outcome. "I trained an LLM on all of Elon's knowledge" sounds one way from a random person, another way from Elon himself. The model can't buy that.
If your edge doesn't sit in one of those four moats, it's worth asking yourself that uncomfortable question sooner rather than later.
Want to rebuild your product around agentic engineering?
I'll help you assess which paradigm you're in, where your moat is, and how to deploy agents without dropping the quality bar - from context architecture to verification loops.
Book a free consultationUseful Resources
- Andrej Karpathy: From Vibe Coding to Agentic Engineering - Sequoia Capital, 29:49. The primary source for the whole thesis: vibe→agentic, verifiability, jagged intelligence.
- Kaparthy revealed the most profitable business to build (Software 3.0) - Dream Labs AI, 14 min. The business angle on the paradigms and the four moats.
- Vibe coding: a guide - how to raise the floor, the other side of this distinction.
- A Karpathy-style knowledge base - how to build the data and context moat.
FAQ
How does Software 3.0 differ from Software 1.0 and 2.0 according to Karpathy?
Software 1.0 is writing explicit code rule by rule, Software 2.0 is programming by curating data and training neural-network weights, and Software 3.0 is prompting - steering the LLM through the context window. In 3.0, what you put into the context window becomes your lever over the model treated as an interpreter. The practical consequence: instead of building a tool, you design a system around an LLM engine that delivers a finished outcome.
What's the difference between vibe coding and agentic engineering?
Vibe coding "raises the floor" - it lets anyone build software, which is democratizing. Agentic engineering "preserves the ceiling" - it's an engineering discipline focused on keeping the professional quality bar (no new vulnerabilities, accountability for the code) while accelerating with the help of agents. In short: vibe coding is accessibility, agentic engineering is quality under the pressure of speed.
What is jagged intelligence in AI models?
Jagged intelligence is the phenomenon where a model has peaks of capability in verifiable domains, like code or math, and valleys in other tasks. It stems from training in RL environments with verification rewards - the model is excellent where the result can be checked automatically. Hence the paradox: the same model will refactor 100,000 lines of code yet stumble on a simple everyday task.
What can't you outsource to AI agents when building a product?
You can't outsource understanding, judgment, and oversight - as Karpathy puts it, "you can outsource your thinking, but you can't outsource your understanding." The human stays the owner of the specification, the plan, and the top-level design, while the agent fills in the blanks. Fundamentals matter too (understanding what happens underneath), because an agent can make a nonsensical mistake it won't catch on its own.
How do you build an "agent-native" product, for agents and not just humans?
Describe systems to agents first (e.g. a block of instructions to paste, not human-oriented documentation), decompose work into sensors that read the world and actuators that act on it, and keep data legible to the LLM. The goal is a world where "my agent talks to your agent." It's also worth refactoring hiring: instead of puzzles, give a real project and watch how the candidate wields the tooling.