Załóż katalog z szablonu
Cel tej lekcji: przejść od „Use this template” do gotowej, uzbrojonej struktury bazy. Po lekcji rozumiesz koncept LLM Wiki, masz własne repo z szablonu i wiesz, dlaczego ta baza działa bez embeddings (liczbowych reprezentacji tekstu do wyszukiwania) i bez RAG (techniki, w której model przy każdym pytaniu przeszukuje surowe dokumenty) - architektura trzech warstw, trzy indeksy i zasada progressive disclosure (czytania od ogółu do szczegółu).
Po co to
LLM Wiki (koncept Karpathy'ego) odwraca RAG: zamiast za każdym razem przeszukiwać surowe dokumenty, agent przyrostowo buduje i utrzymuje żywą bazę markdown - z linkami, indeksami, syntezami. Wiedza kumuluje się i jest czytelna i dla agenta, i dla człowieka (otwierasz plik, czytasz). Standard OKF (Open Knowledge Format, Google) formalizuje ten wzorzec → bazy są przenośne.
Weź szablon
Na GitHubie „Use this template” (albo git clone) → własne repo. Otwórz folder w Claude Code. Opcjonalnie npm install (Prettier - formatowanie) i pip install -r requirements.txt (skille pythonowe) - do pierwszego pytania niepotrzebne. Publikację przez Quartz doklejasz później (lekcja 5).
Repo szablonu: github.com/plipowczan/second-brain-template.
Krok po kroku: z szablonu do VS Code
Cały proces masz na wideo u góry. Poniżej to samo w krokach - ścieżka przez przeglądarkę + GitHub Desktop (najprościej dla każdego).
1. Wejdź na repo szablonu. github.com/plipowczan/second-brain-template. Zielony przycisk „Use this template” w prawym górnym rogu.
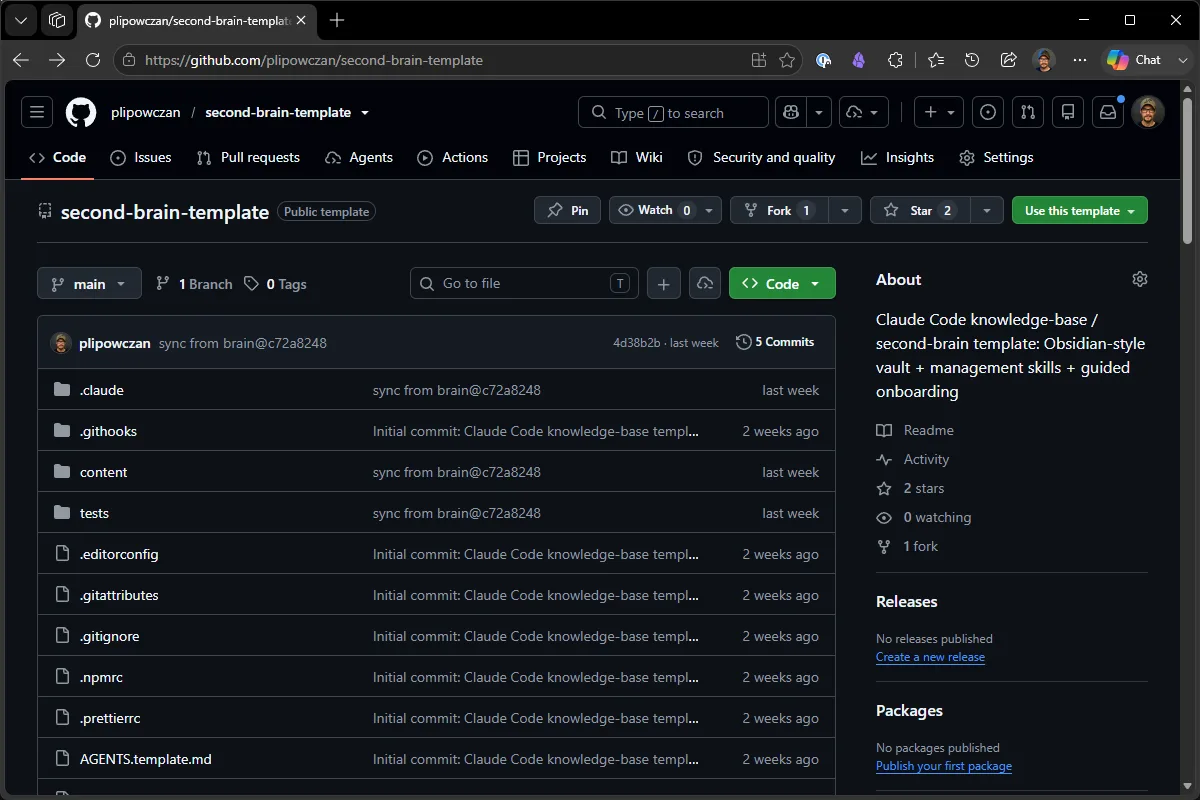
2. „Use this template” → „Create a new repository”. Właściciel = Ty, Repository name = np. brain-test, widoczność Public lub Private (Twój wybór). Kliknij „Create repository”.
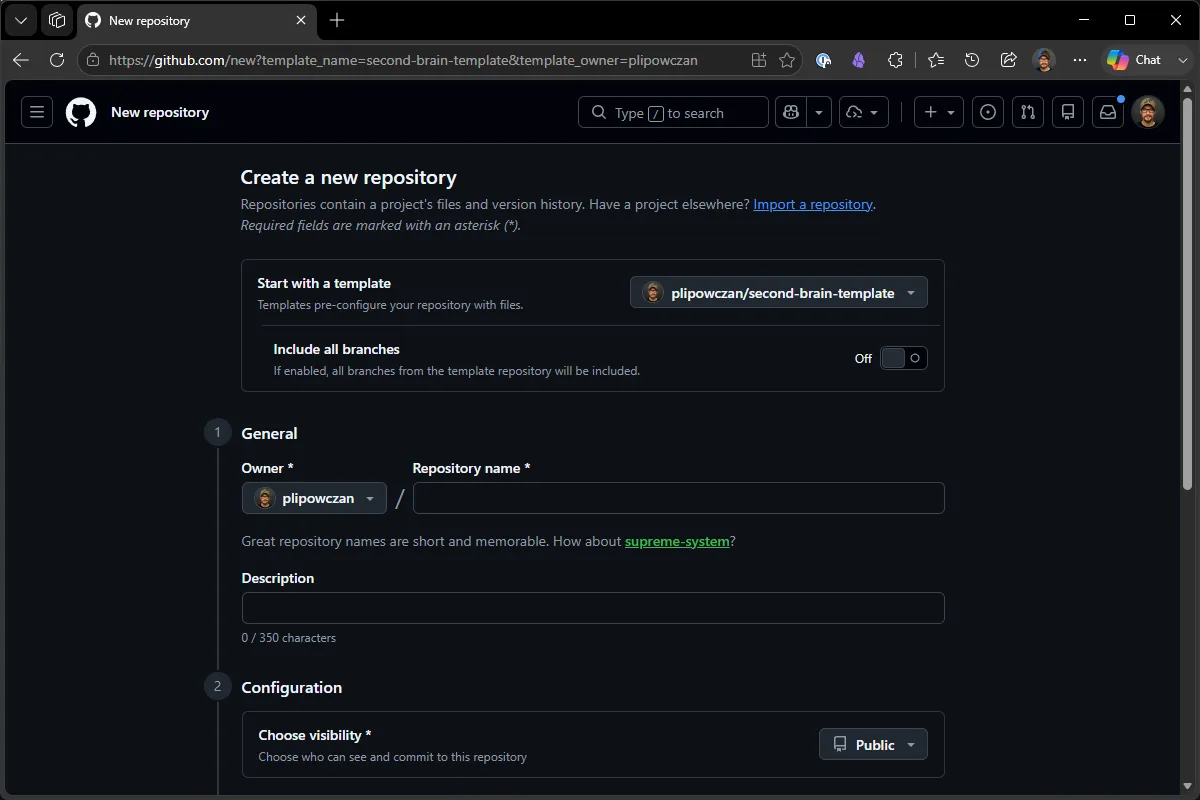
Po chwili masz własne repo z całą zawartością szablonu (tu: brain-test):
3. Sklonuj repo lokalnie. Zielony „Code” → „Open with GitHub Desktop” (albo skopiuj URL HTTPS i użyj git clone).
4. W GitHub Desktop potwierdź URL repo i Local path (np. C:\Projects\brain-test), potem Clone.
5. Otwórz w edytorze. Po sklonowaniu GitHub Desktop proponuje „Open in Visual Studio Code” (Ctrl+Shift+A).
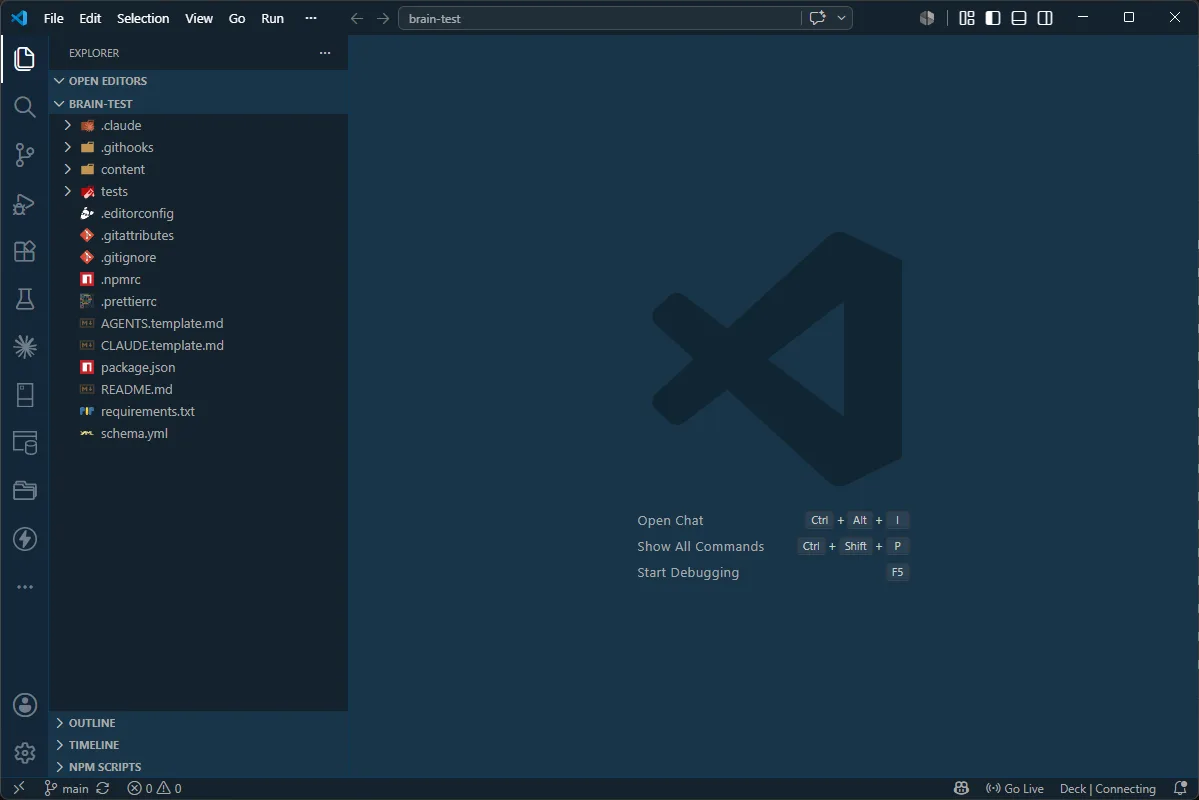
6. Gotowe - VS Code otwarty na brain-test. W Explorerze widzisz całą strukturę szablonu. Co jest czym - niżej.
🤖 Gotowy prompt - niech agent założy repo
Ścieżka przez przeglądarkę („Use this template” wyżej) jest najprostsza. Jeśli wolisz, żeby Claude Code sam utworzył Twoje repo i sklonował je lokalnie - otwórz Claude Code w folderze na projekty i wklej (podmień <nazwa-repo>):
Utwórz moje własne repo z szablonu second-brain i sklonuj je tutaj.
Szablon: github.com/plipowczan/second-brain-template.
Jeśli mam zalogowane gh CLI, użyj:
gh repo create <nazwa-repo> --template plipowczan/second-brain-template --private --clone
W przeciwnym razie zrób git clone szablonu do folderu <nazwa-repo> i wyjaśnij,
jak później podmienić origin na moje własne repo.
Po sklonowaniu wejdź do folderu, potwierdź strukturę (CLAUDE.template.md,
content/_raw/inbox/, content/_indexes/, .claude/commands/) i powiedz, czy mogę
odpalić /onboard. Poza klonowaniem niczego nie zmieniaj.
Agent założy repo, sklonuje, zweryfikuje strukturę i da zielone światło na lekcję 2.
Tak to wygląda w praktyce - prompt odpalony w terminalu Claude Code (wklejenie, podmiana <nazwa-repo>, uruchomienie, efekt w VS Code):
Co jest w repo (po utworzeniu z szablonu)
Świeży klon wygląda tak (to samo drzewo widać w Explorerze VS Code wyżej):
brain-test/
.claude/ commands + skills + hooks - mózg agenta
.githooks/ pre-commit - higiena przed commitem
content/ Twój vault (rozwinięcie niżej)
tests/ run_tests.py - testy skryptów skilli
CLAUDE.template.md · AGENTS.template.md schema agenta ({{placeholdery}})
content/WRITING_STYLE.template.md szablon Twojego głosu
schema.yml kontrakt frontmatteru per typ noty
README.md · package.json · requirements.txt
.editorconfig · .gitattributes · .gitignore · .npmrc · .prettierrc
Foldery:
- .claude/ - mózg agenta. commands/ to slash-komendy (/onboard, /ingest, /qa, /lint, /reindex, /gaps, /curate, /compile, /enhance, /output, /refactor), skills/ to ich implementacje (m.in. pythonowe: reindex, lint, ingest, gaps + skille research i excalidraw-diagram). hooks/load_vault_map.py auto-ładuje mapę bazy na starcie każdej sesji, a settings.json to konfiguracja Claude Code.
- .githooks/ - hook pre-commit: kontrola jakości (format/lint), zanim cokolwiek trafi do commita.
- content/ - Twój vault (tak nazywamy folder z całą Twoją wiedzą): noty, indeksy, szablony i wzorce (rozbicie niżej).
- tests/ - run_tests.py, testy skryptów pythonowych skilli. Nie ruszasz na co dzień - są, żeby mechanika była pewna.
Pliki schemy (znikają po /onboard):
- CLAUDE.template.md / AGENTS.template.md - kontrakt agenta z placeholderami, czyli polami do podmiany ({{KB_NAME}}, {{KB_OWNER}}, {{TOPIC_TABLE}}, ...). /onboard wypełnia je i zapisuje jako CLAUDE.md / AGENTS.md. Ich obecność to znak, że baza jest jeszcze nieskonfigurowana.
- content/WRITING_STYLE.template.md - szablon Twojego „głosu” (osoba, formalność, emoji w nagłówkach). /onboard wypełnia go i zapisuje jako content/WRITING_STYLE.md.
Pozostałe pliki:
- schema.yml - kontrakt frontmatteru (bloku metadanych na początku pliku) per typ noty: jakie pola są wymagane (np. knowledge-note musi mieć title, date, type, tags, summary). /lint to egzekwuje. Skasujesz plik → luźniejszy tryb, bez wymuszania pól.
- README.md - opis szablonu i quickstart.
- package.json - jedyny skrypt to npm run format (Prettier). Potok publikacji (Quartz) świadomie nie wchodzi w zestaw - doklejasz go później (lekcja 5).
- requirements.txt - zależności Pythona skryptów (PyYAML; yt-dlp opcjonalnie, pod /ingest z YouTube).
- .editorconfig · .gitattributes · .gitignore · .npmrc · .prettierrc - standardowa higiena repo (styl kodu, końcówki linii, ignorowane pliki, format).
W środku content/:
- _raw/inbox/ - miejsce na surowe źródła (jest gotowy sample-source.md na rozgrzewkę). Po /ingest źródła lądują w _raw/processed/.
- _indexes/ - trzy auto-utrzymywane indeksy nawigacyjne: vault-map.md, catalog.md, graph.md (serce progressive disclosure - patrz niżej).
- _outputs/ - answers/ (zapisane odpowiedzi /qa) i reports/ (raporty /lint).
- _graveyard/ - wycofane noty: odwracalne, wykluczone z indeksów (/curate je tam odkłada).
- templates/ - szablony not per typ: basic_notes.md, book.md, knowledge_note_info.md, knowledge_note_how_to.md, tool.md.
- REFERENCE/ - wzorce na start: Example Note.md i Wikilinks Explained.md (jak wygląda dobra nota i jak działają [[linki]]).
To „pusty, ale uzbrojony” brain - cała mechanika gotowa, brak tylko Twojej wiedzy.
Architektura - 3 warstwy
| Warstwa | Gdzie | Kto włada |
|---|---|---|
| Raw sources | _raw/inbox → _raw/processed | Ty wrzucasz, agent tylko czyta |
| Wiki | content/<TOPIC>/ | Agent tworzy/utrzymuje noty |
| Schema | CLAUDE.md (z onboardingu) | Ty + agent współ-ewoluujecie |
Dlaczego to działa bez RAG: progressive disclosure
Progressive disclosure to jedna zasada: najpierw pokaż, co istnieje i ile kosztuje pobranie - niech agent sam zdecyduje, co wczytać. Tak jak człowiek skanuje spis treści przed rozdziałem albo nazwy plików, zanim któryś otworzy.
Porównaj dwa podejścia do tego samego pytania:
- Klasyczny RAG - „wrzuć wszystko”. Do kontekstu ląduje np. 35 000 tokenów notatek i historii, z czego realnie trafne jest może 2 000. Efektywność ~6%. Reszta zabiera uwagę modelu i miejsce na właściwe zadanie.
- Index-first - progressive disclosure. Agent czyta najpierw indeks (~kilkaset tokenów): co istnieje, jakiego typu, z jakimi tagami. Na tej podstawie pobiera tylko 2-3 trafne noty (~kilkaset tokenów). Trafność bliska 100%, a okno kontekstu zostaje wolne na myślenie.
To dlatego baza działa bez embeddings i bez RAG do ~500 źródeł: nie trzeba liczyć wektorów, gdy dobry indeks pozwala agentowi zawęzić wyszukiwanie samą lekturą.
3 indeksy - trzy poziomy powiększenia
Trzy indeksy w content/_indexes/ to ten sam vault widziany z trzech odległości. Agent zaczyna z lotu ptaka i przybliża dopiero tam, gdzie trzeba.
vault-map.md - mapa z lotu ptaka (L0)
Co gdzie leży: tabela folderów (ile not, jakie typy, dominujące tagi), chmura tagów i lista ostatnich zmian. Jedna „strona”, z której agent wybiera folder, nie notę.
---
updated: 2026-06-30T12:00:00Z
total_notes: 330
---
# Vault Map
## Folders
| folder | notes | types | top-tags |
|--------------------|------:|--------------------|-------------------------------------|
| AI/KNOWLEDGE/INFO | 28 | knowledge-note(27) | ai, agents, context-engineering |
| AI/TOOLS | 69 | tool(69) | tool, claude-code, agents |
| CODE/TOOLS | 40 | tool(40) | frontend, framework, infrastructure |
## Tag Cloud
agents:29 ai:119 claude-code:38 context-engineering:11 rag:10 skills:16 ...
## Recent Changes
- 2026-06-30 AI/TOOLS/Ponytail (ingest - vibe-coding skill: YAGNI-first, −54% LOC)
- 2026-06-25 CODE/TOOLS/Git (enhance - uzupełniony stub + linki)
Czytając to, agent od razu wie: „temat o agentach i tokenach? → folder AI/KNOWLEDGE/INFO”. Zawęża, zanim cokolwiek otworzy.
catalog.md - jedna linia na notę (L1)
Katalog wszystkich not, pogrupowany folderami. Każda nota to jedna linia: tytuł, typ, data, tagi, jednozdaniowe streszczenie i lista wychodzących linków.
## AI/KNOWLEDGE/INFO
- **Context Engineering** | knowledge-note | 2026-04-09 | [ai, context-engineering] | Zarządzanie tym, co trafia do okna kontekstu agenta - indeksy, kompresja, progressive disclosure. | → Progressive Disclosure, Agent Skills, Claude Code
- **Progressive Disclosure** | knowledge-note | 2026-04-30 | [ai, memory] | Pokaż najpierw co istnieje i ile kosztuje pobranie; agent sam decyduje, co wczytać. | → Context Engineering, Harness Engineering
Format linii: **Tytuł** | typ | data | [tagi] | streszczenie | → linki. Po streszczeniach agent wybiera konkretne noty do otwarcia - wciąż nie czytając ich treści.
graph.md - graf połączeń (L2)
Kto z kim linkuje. Dzięki temu agent po otwarciu jednej noty wie, które sąsiednie dociągnąć, żeby spiąć temat.
## Outgoing
AI/KNOWLEDGE/INFO/Context Engineering -> AI/KNOWLEDGE/INFO/Progressive Disclosure, AI/TOOLS/Agent Skills, AI/TOOLS/Claude Code
AI/KNOWLEDGE/INFO/Progressive Disclosure -> AI/KNOWLEDGE/INFO/Context Engineering, AI/KNOWLEDGE/INFO/Harness Engineering
Jak agent tego używa - przykład /qa
Zapytanie: /qa "jak ograniczyć zużycie tokenów w agencie?"
- vault-map (L0): agent czyta mapę (~jedna strona). Widzi, że temat pasuje do AI/KNOWLEDGE/INFO (tagi context-engineering, token-optimization). Zawęża do tego folderu.
- catalog (L1): czyta tylko linie tego folderu. Po streszczeniach wybiera 2 noty: „Token Optimization for Claude Code” i „Progressive Disclosure”.
- Pełne noty (Layer 2): otwiera tylko te 2 - nie 330.
- graph (L2): widzi, że obie linkują do „Context Engineering”, więc dociąga ją, bo spina temat.
Efekt: agent przeczytał ~3 noty zamiast całej bazy. Kilkaset tokenów indeksu + kilka trafnych not - zamiast wrzucania wszystkiego. To jest progressive disclosure w akcji.
Wzorzec - jak wygląda dobra nota
Zajrzyj do REFERENCE/Example Note.md i Wikilinks Explained.md - jak wygląda dobra nota i jak działają linki. Dobra nota ma frontmatter z type, jednozdaniowe summary (to trafia do katalogu) i kilka celnych [[wikilinków]] (to zasila graf).
Pułapka
Nie pisz wiki ręcznie - to robota agenta; Ty dostarczasz źródła i dobre pytania. Nie edytuj też indeksów z palca - buduje je /ingest i /reindex (o tym w lekcjach 3 i 4).
FAQ
Czym LLM Wiki różni się od RAG i baz wektorowych?
RAG za każdym pytaniem przeszukuje surowe dokumenty i wrzuca do kontekstu masę tekstu, z którego trafna jest garstka. LLM Wiki odwraca to: agent czyta najpierw lekki indeks (co istnieje, jakiego typu, z jakimi tagami) i dociąga tylko 2-3 trafne noty. Nie liczy wektorów ani embeddingów - do ~500 źródeł dobry indeks wystarcza, żeby zawęzić wyszukiwanie samą lekturą.
Agent ma grep - po co mu jeszcze indeks?
Grep (wyszukiwanie w plikach po dokładnym słowie) wystarcza, gdy baza jest mała, a Ty znasz szukane słowo - i agent wciąż go używa. Problem zaczyna się ze skalą: przy setkach not częste słowo zwraca dziesiątki trafień, agent wczytuje je wszystkie i okno kontekstu puchnie. Do tego grep nie zna synonimów - szukając „składki zdrowotnej”, nie znajdzie „ubezpieczenia zdrowotnego”; opisy i linki w indeksie niosą znaczenie, nie tylko ciąg znaków. Indeks nie zastępuje grepa: najpierw zawęża zakres do 2-3 właściwych not, a grep szuka już tylko wewnątrz nich.
Czy do startu muszę odpalać npm install i pip install?
Nie, do pierwszego pytania nie są potrzebne. npm install instaluje tylko narzędzia dev (Prettier - formatowanie), a pip install -r requirements.txt - zależności skryptów pythonowych (/reindex, /lint, /ingest, render.py). Publikację przez Quartz doklejasz osobno w lekcji 5. Sama struktura i noty to zwykły markdown - możesz zacząć od razu.
Repo z szablonu - publiczne czy prywatne?
Twój wybór; baza to zwykłe repo git i działa tak samo w obu trybach. Prywatne, jeśli to Twoja osobista wiedza (domyślnie bezpieczniej). Publiczne - jeśli od razu chcesz ją publikować lub dzielić się nią jako paczką OKF. Widoczność zmienisz w każdej chwili w ustawieniach repo.
Czy potrzebuję płatnych narzędzi albo zewnętrznej bazy danych?
Szablon jest darmowy, a cała baza to pliki markdown w Twoim repo - żadnej zewnętrznej bazy danych, wektorowej usługi ani API do przechowywania wiedzy. Potrzebujesz Claude Code do pracy z agentem oraz (opcjonalnie) Pythona do skryptowych skilli. Nic nie wychodzi na zewnątrz, dopóki sam nie opublikujesz.
Co znaczy, że baza jest „pusta, ale uzbrojona”?
Cała mechanika jest gotowa od pierwszej minuty: slash-komendy, skille, trzy indeksy nawigacyjne, hook ładujący mapę vaultu, kontrakt frontmatteru (schema.yml) i szablony not. Brakuje wyłącznie Twojej wiedzy. Nie budujesz narzędzi - od razu ich używasz, a baza rośnie z każdym źródłem.
Co, gdy baza urośnie powyżej ~500 źródeł?
Progressive disclosure skaluje się dalej - indeks i graf rosną wolniej niż treść, więc agent nadal zawęża zanim otworzy notę. Przy bardzo dużych bazach można podzielić wiedzę na tematyczne podbazy (multi-brain, lekcja 5) albo dołożyć warstwę wyszukiwania. Granica ~500 to moment, w którym warto o tym pomyśleć, a nie twardy limit.
Zostaw maila - dam znać, gdy ruszą gotowe paczki wiedzy.
Zapisz się na listę →