Onboarding
Cel tej lekcji: przejść cały onboarding krok po kroku (onboarding = pierwsza konfiguracja bazy) na konkretnym przykładzie. Po lekcji masz wygenerowaną schema (CLAUDE.md - plik zasad Twojej bazy), foldery tematów i puste, ale gotowe indeksy - i wiesz dokładnie, co dzieje się pod spodem.
Prowadzę Cię przez realny przebieg (screeny z prawdziwej sesji): Anna stawia bazę „Baza Anny” po polsku, na tematach AI, BUSINESS, HEALTH. Twoje odpowiedzi będą inne - proces jest ten sam.
Warunek startu
Onboarding odpalasz raz, na świeżym klonie. Kreator rozpoznaje świeży klon po obecności pliku CLAUDE.template.md w repo. Otwórz folder w Claude Code i wpisz:
/onboard
Jeśli CLAUDE.template.md już nie istnieje (baza była konfigurowana), kreator nie nadpisze niczego - zaproponuje ponowną konfigurację (patrz „Powtarzalność” niżej).
Faza 1 - Wywiad (jedno pytanie na raz)
Kreator prowadzi sześć pytań, pojedynczo - wybierasz z gotowych opcji albo wpisujesz swoje. Po każdej odpowiedzi powtarza wybór i zapowiada następne pytanie, więc widzisz cały ślad decyzji. Poniżej realny przebieg „Bazy Anny”.
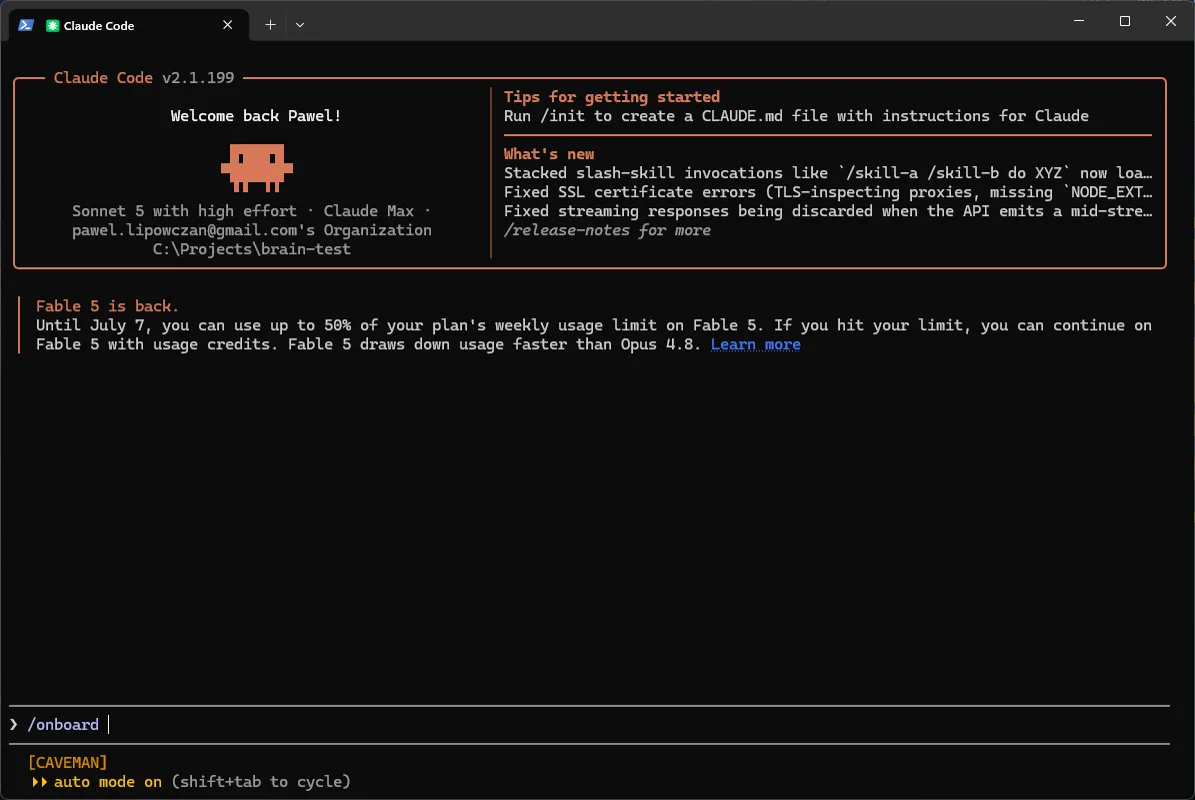
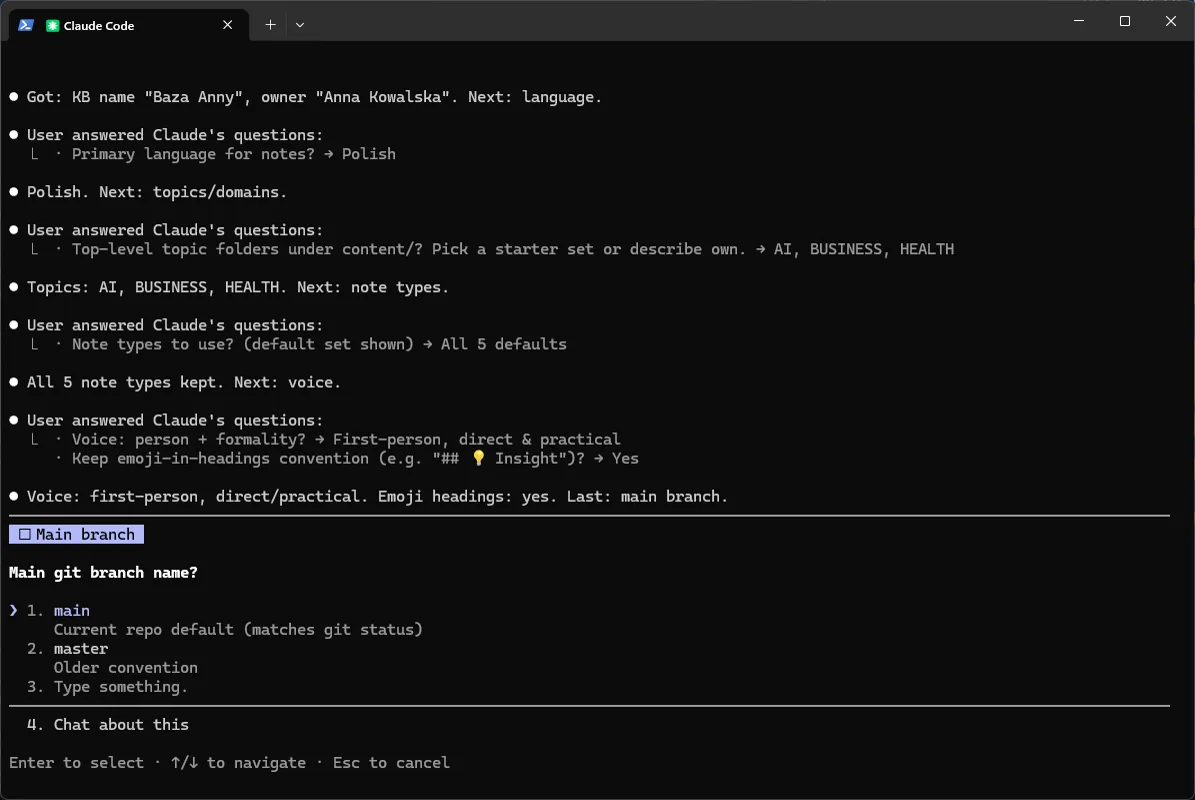
Q1 - Nazwa bazy i właściciel. Wolny tekst; kreator podpowiada warianty (np. z Twojej tożsamości git). Anna wpisuje Baza Anny · Anna Kowalska.
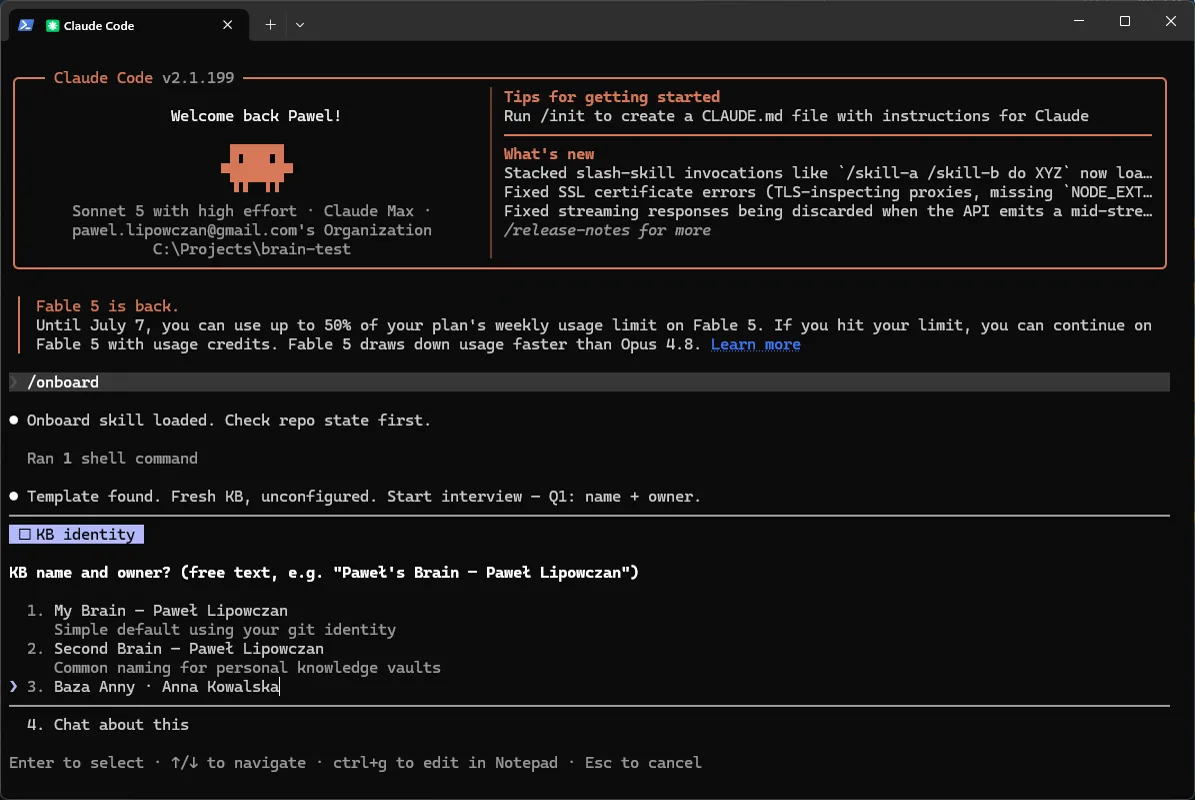
Q2 - Główny język. Język, w którym agent pisze noty i streszczenia. Anna: Polish.
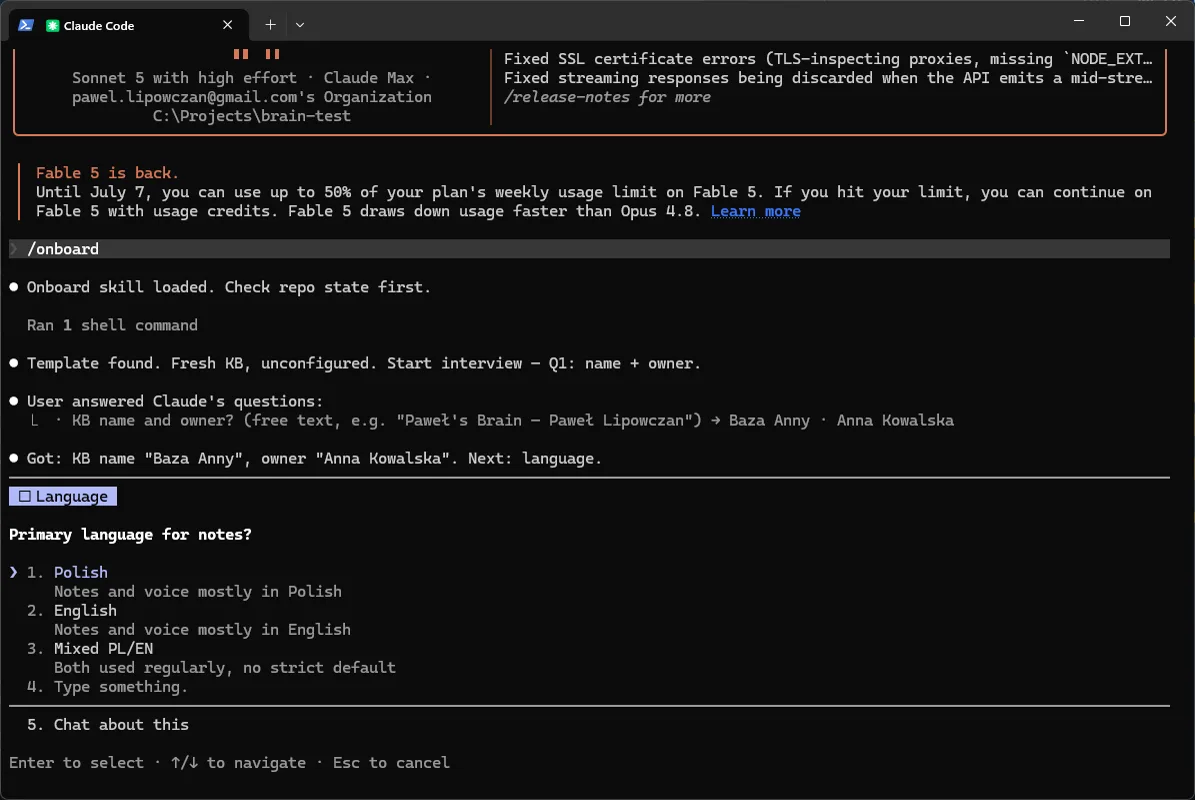
Q3 - Tematy / domeny. Foldery najwyższego poziomu pod content/ - szerokie działy, nie szczegóły. Kreator proponuje gotowe zestawy; Anna wybiera AI, BUSINESS, HEALTH.
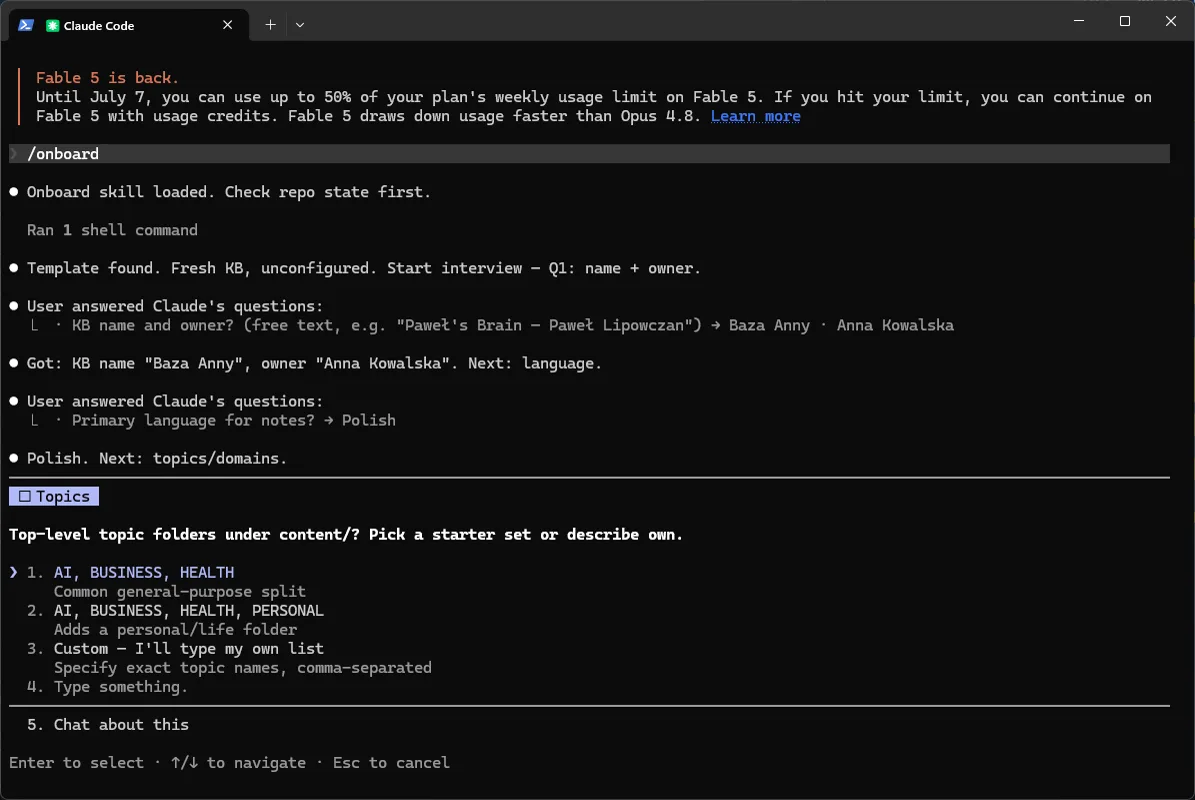
Q4 - Typy not. Domyślnie 5: basic-note, knowledge-note, tool, book-note, answer-note. Anna zostawia wszystkie 5.
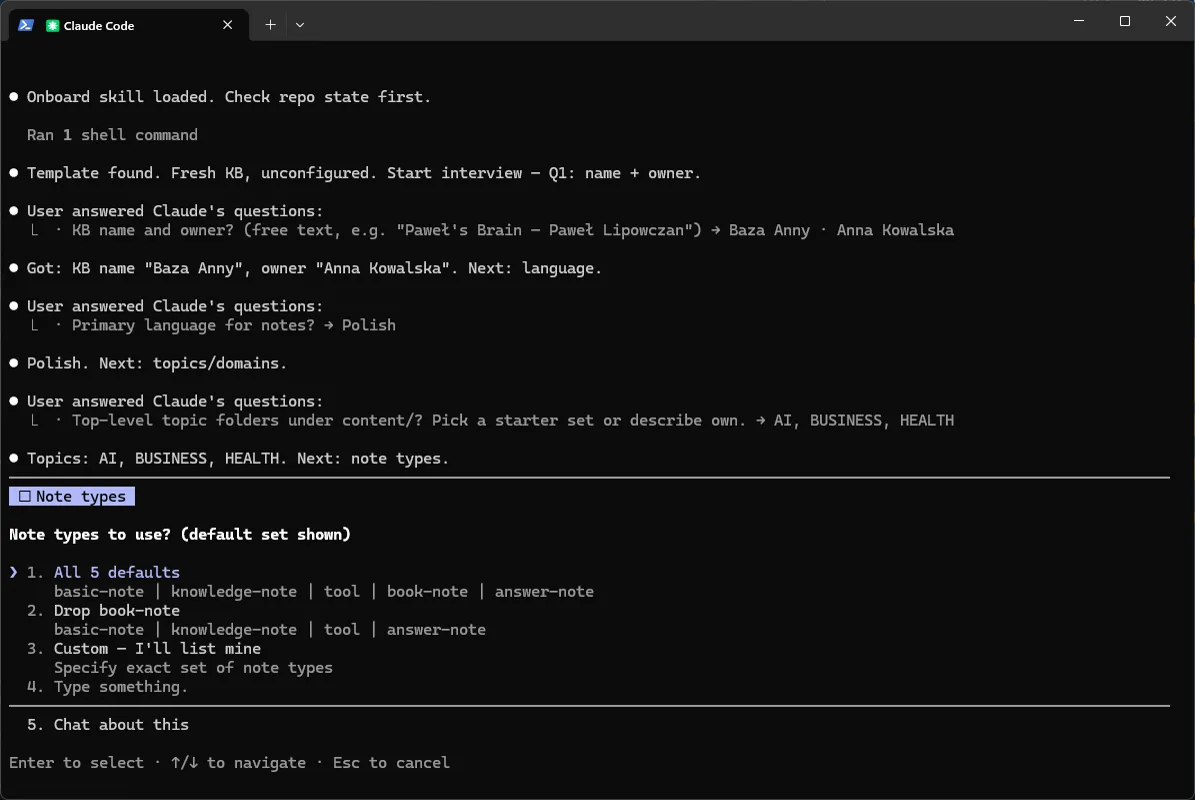
Q5 - Głos. Osoba + formalność. Anna: first-person, direct & practical („Notuję”, ton casual-professional).
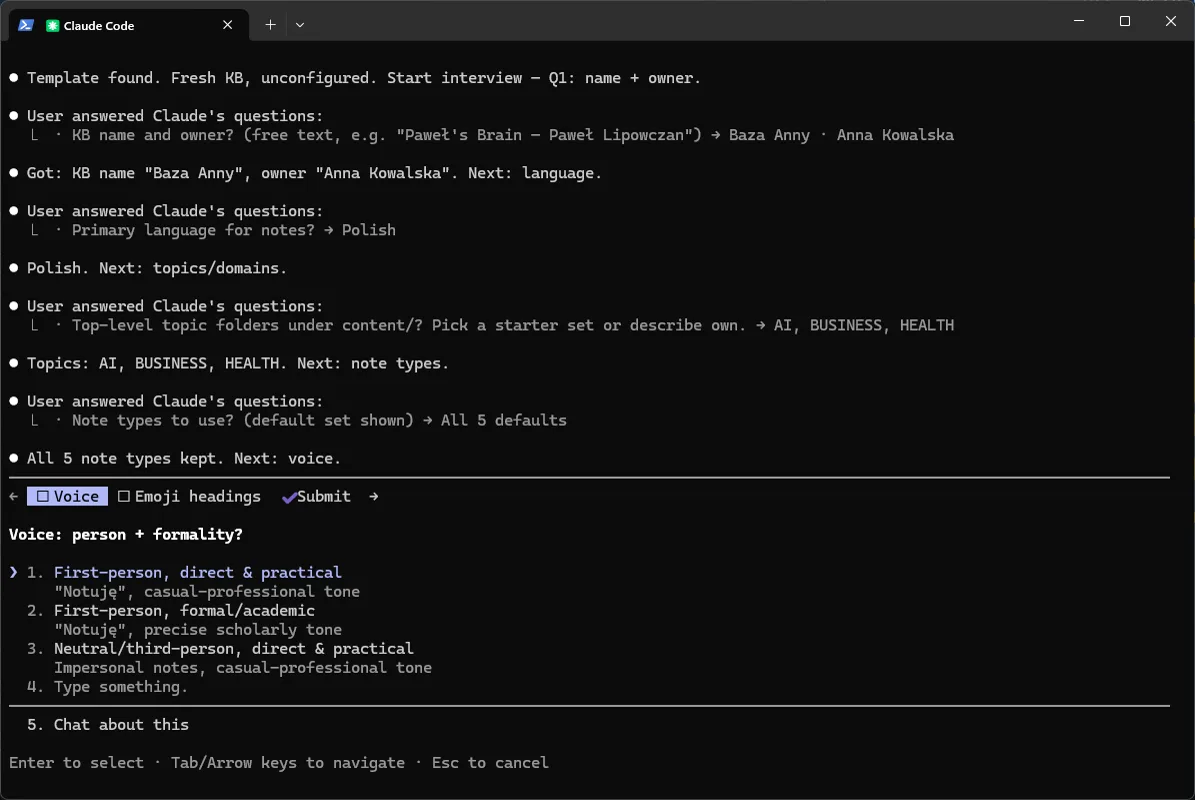
To samo pytanie ma drugą zakładkę - emoji w nagłówkach (## 💡 Insight). Anna zostawia Yes.
Głos + emoji zatwierdzasz razem - kreator pokazuje przegląd przed wysłaniem:
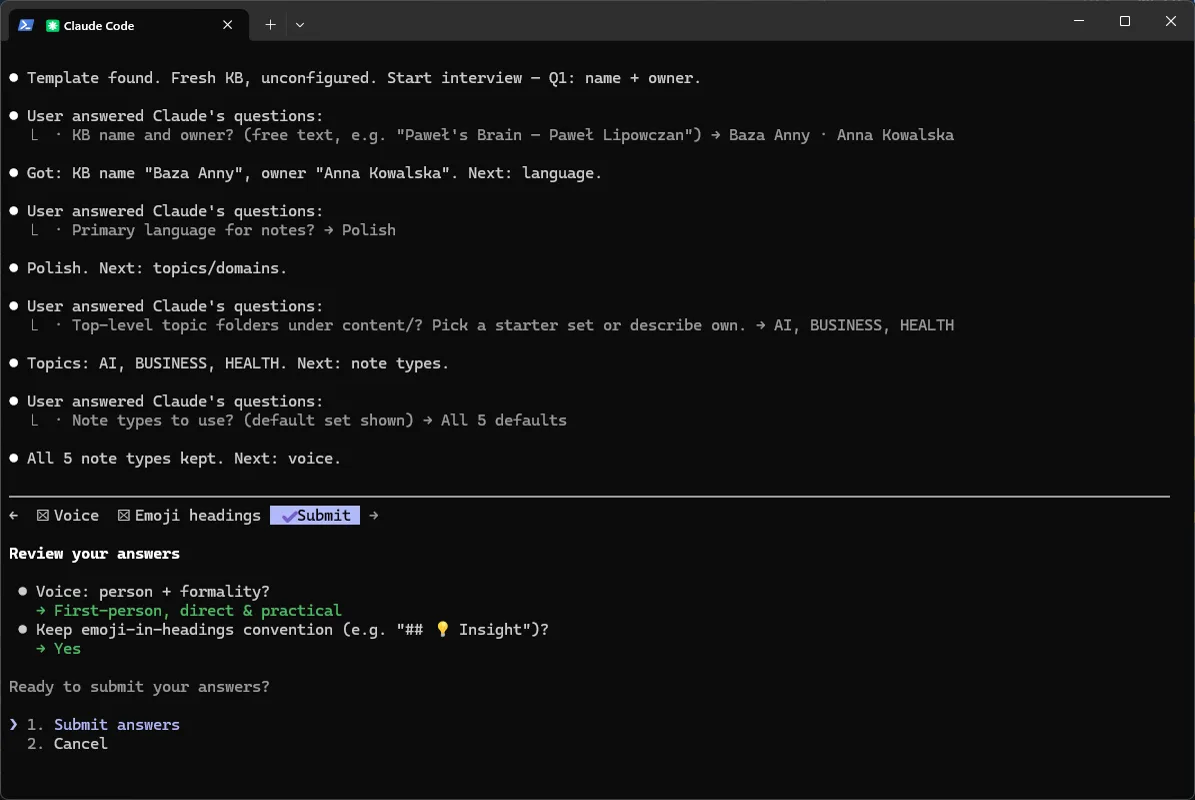
Q6 - Główna gałąź. Domyślnie main (pasuje do repo). Anna: main.
Faza 2 - Generowanie (deterministyczne)
Po ostatnim pytaniu kreator działa sam. Najpierw zapisuje odpowiedzi do .kb-onboard.json w korzeniu repo (to stąd bierze się jej powtarzalność):
{
"KB_NAME": "Baza Anny",
"KB_OWNER": "Anna Kowalska",
"PRIMARY_LANGUAGE": "Polish",
"MAIN_BRANCH": "main",
"VOICE_PERSON": "first-person",
"VOICE_FORMALITY": "direct and practical",
"NOTE_TYPES": "basic-note | knowledge-note | tool | book-note | answer-note",
"emoji_headings": true,
"TOPIC_TABLE": "| `/content/AI/` | AI, agents, and tooling notes | Yes |\n| `/content/BUSINESS/` | Sales, marketing, operations notes | Yes |\n| `/content/HEALTH/` | Health, fitness, and wellbeing notes | Yes |"
}
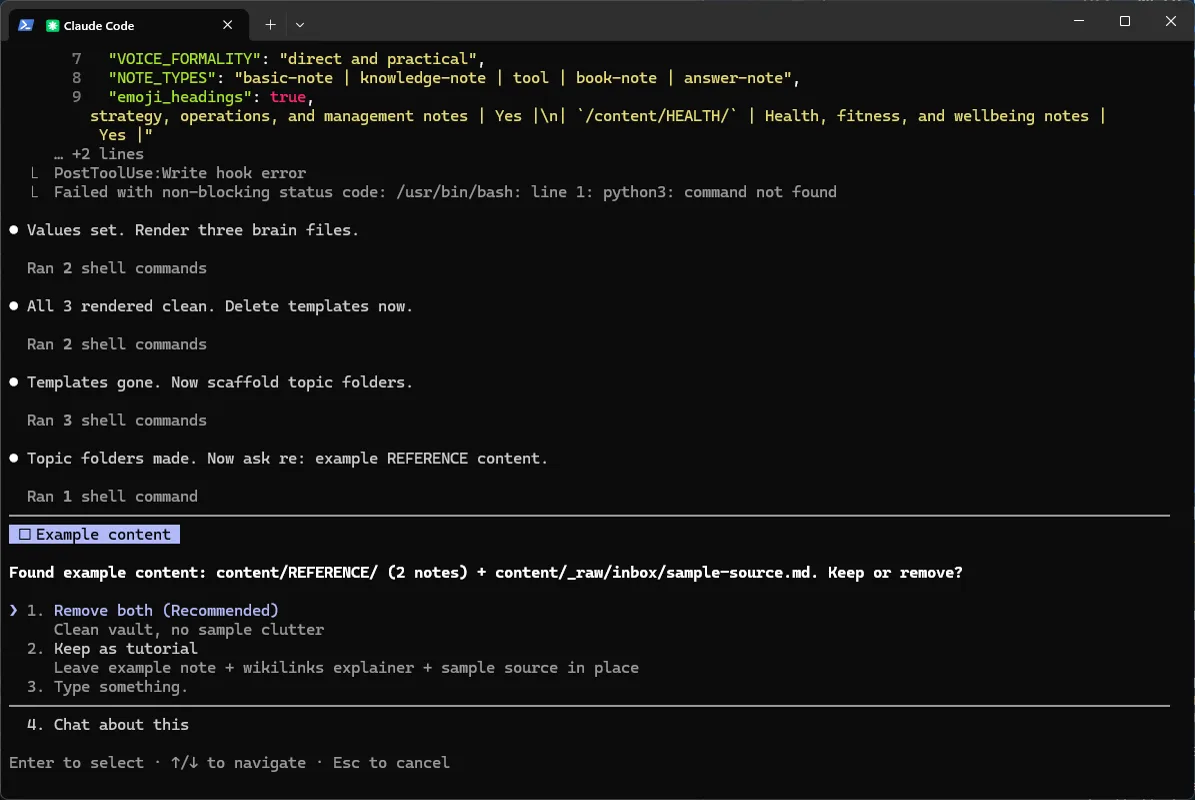
Potem, krok po kroku (widać to na screenie):
- Wypełnia trzy pliki schematu z szablonów (skrypt render.py): CLAUDE.md, AGENTS.md, content/WRITING_STYLE.md.
- Kasuje szablony (*.template.md) - dopiero gdy wszystkie trzy pliki wygenerują się poprawnie.
- Tworzy foldery tematów pod content/: AI/, BUSINESS/, HEALTH/.
- Pyta o przykłady: content/REFERENCE/ (2 noty) + content/_raw/inbox/sample-source.md - usunąć czy zostawić jako samouczek. Anna wybiera „Keep as tutorial”.
- Przycina szablony not do wybranych typów (tu wszystkie 5 zostają - nic nie ubywa).
- Przebudowuje indeksy (build_indexes.py).
Faza 3 - Gotowe (podsumowanie + przekazanie)
Kreator drukuje podsumowanie: co powstało i co dalej.
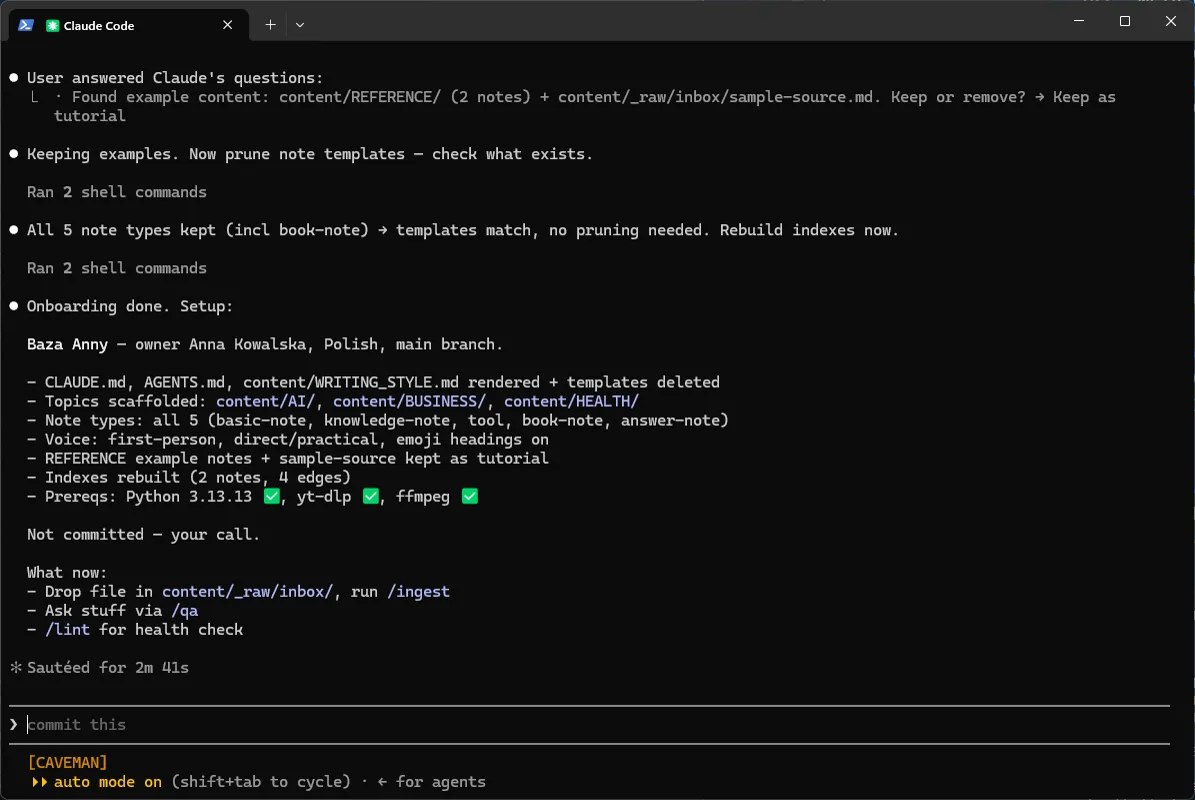
Dla „Bazy Anny” wyszło:
- CLAUDE.md, AGENTS.md, content/WRITING_STYLE.md wygenerowane, szablony skasowane,
- foldery tematów: content/AI/, content/BUSINESS/, content/HEALTH/,
- typy not: wszystkie 5; głos first-person direct/practical; emoji w nagłówkach: on,
- REFERENCE/ + sample-source zostawione jako samouczek,
- indeksy przebudowane - 2 noty, 4 krawędzie (to te 2 przykładowe noty),
- zależności: Python 3.13 ✅, yt-dlp ✅, ffmpeg ✅ (Python wymagany do reindex/lint/render; yt-dlp+ffmpeg opcjonalne, pod /ingest z YouTube).
Repo po fazie:
content/
AI/ .gitkeep
BUSINESS/ .gitkeep
HEALTH/ .gitkeep
REFERENCE/ Example Note.md · Wikilinks Explained.md (zostawione jako samouczek)
_indexes/ vault-map.md · catalog.md · graph.md (przebudowane: 2 noty, 4 krawędzie)
templates/ (5 typów not)
CLAUDE.md ← wygenerowany (schema Twojej bazy)
AGENTS.md ← wygenerowany
content/WRITING_STYLE.md ← wygenerowany (Twój głos)
Szablony *.template.md zniknęły - to znak, że baza jest zainicjalizowana. Kreator nie robi żadnego commita („Not committed - your call”).
Co teraz (kreator podpowiada):
- wrzuć plik do content/_raw/inbox/ i odpal /ingest (lekcja 3),
- zadaj pytanie przez /qa (lekcja 4),
- odpal /lint na przegląd stanu bazy (lekcja 4).
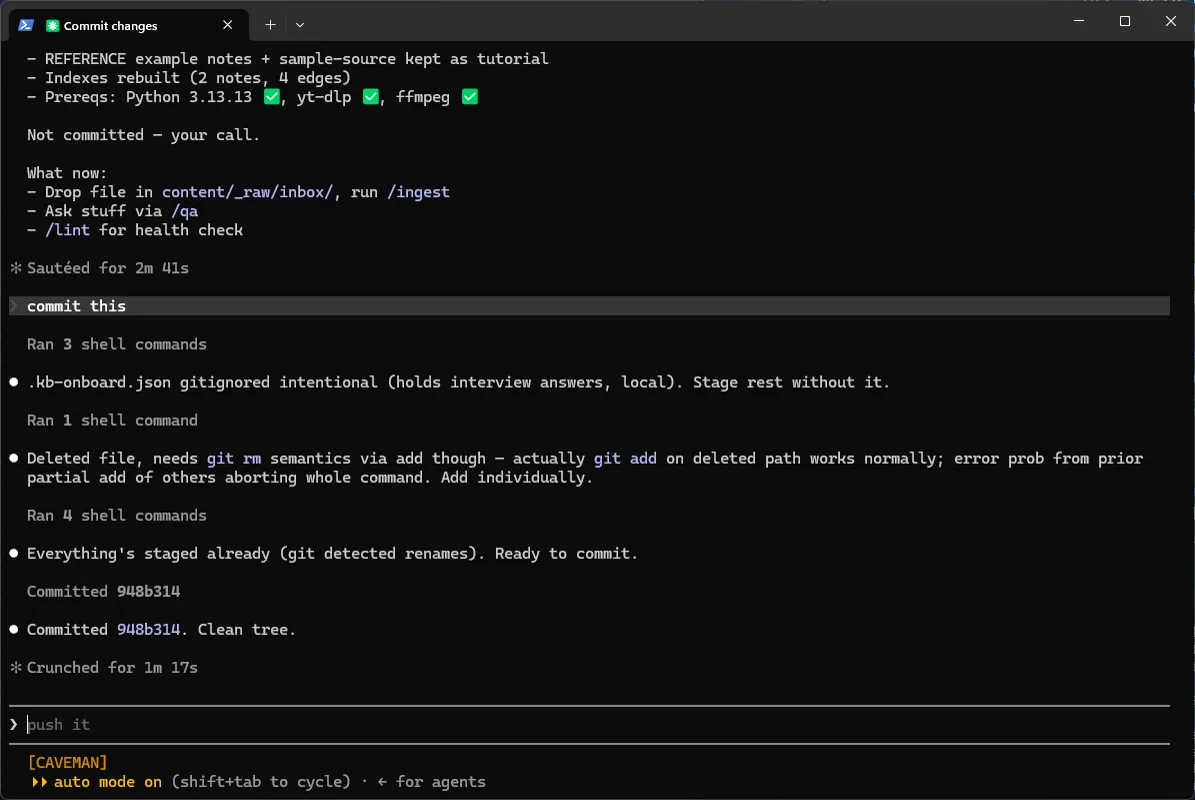
Zapisz stan (git)
Baza to zwykłe repo git - pierwszy commit robisz jak zawsze. Możesz to nawet zlecić agentowi („commit this”): sam doda pliki i zrobi commit, pomijając .kb-onboard.json (jest pomijany przez gita - trzyma Twoje odpowiedzi lokalnie).
Powtarzalność
Odpowiedzi siedzą w .kb-onboard.json. Gdy odpalisz /onboard ponownie na już skonfigurowanej bazie (brak CLAUDE.template.md), kreator nie nadpisze niczego po cichu - zaproponuje ponowną konfigurację: wczyta .kb-onboard.json, pozwoli poprawić odpowiedzi i przegeneruje pliki, ostrzegając przed nadpisaniem istniejących.
🤖 Szybka ścieżka - onboarding promptem
/onboard prowadzi wywiad pytanie-po-pytaniu (jak wyżej). Jeśli wolisz, żeby Claude Code wykonał wszystko za jednym zamachem, wklej prompt z gotowymi odpowiedziami (podmień <...> na swoje):
Przeprowadź onboarding tej bazy (skill onboard). Moje odpowiedzi:
- nazwa bazy / właściciel: <Baza Anny> / <Anna Kowalska>
- język: polski
- tematy: <AI>, <BUSINESS>, <HEALTH>
- typy not: domyślne
- głos: pierwsza osoba, praktyczny, emoji w nagłówkach: tak
- gałąź główna: main
Wykonaj wszystkie fazy: wygeneruj CLAUDE.md / AGENTS.md / WRITING_STYLE.md,
utwórz foldery tematów, skasuj szablony *.template.md, przytnij szablony not do
wybranych typów i przebuduj indeksy. Na koniec pokaż drzewo repo i podsumowanie.
Efekt ten sam co wywiad - bez klikania. Odpowiedzi lądują w .kb-onboard.json, więc ponowna konfiguracja dalej działa.
Dzień zerowy
To Twój „dzień zerowy” - jedyny moment konfiguracji. Potem już tylko używasz: /ingest, /qa, /lint. Przechodzimy do karmienia bazy w lekcji 3.
FAQ
Ile razy odpalam /onboard?
Raz, na świeżym klonie. Kreator rozpoznaje świeży klon po obecności pliku CLAUDE.template.md. Jeśli odpalisz go ponownie na skonfigurowanej bazie (szablonu już nie ma), nie nadpisze niczego po cichu - zaproponuje ponowną konfigurację.
Co, jeśli wybiorę zły język albo tematy?
Poprawiasz przez ponowny /onboard w trybie ponownej konfiguracji: kreator wczyta Twoje odpowiedzi z .kb-onboard.json, pozwoli je zmienić i przegeneruje pliki, ostrzegając przed nadpisaniem. Foldery tematów to zwykłe katalogi pod content/ - nowe możesz dodać ręcznie w dowolnym momencie, a /reindex odświeży indeksy.
Gdzie zapisują się moje odpowiedzi z wywiadu?
W pliku .kb-onboard.json w korzeniu repo. Jest pomijany przez gita - trzyma Twoje wybory lokalnie i nie trafia do commita. To z niego bierze się powtarzalność: ponowna konfiguracja czyta właśnie ten plik.
Dlaczego szablony *.template.md znikają po onboardingu?
Bo kreator wypełnia je Twoimi wartościami i zapisuje jako finalne pliki: CLAUDE.template.md → CLAUDE.md, AGENTS.template.md → AGENTS.md, content/WRITING_STYLE.template.md → content/WRITING_STYLE.md. Szablony kasuje dopiero gdy wszystkie trzy pliki wygenerują się poprawnie. Ich brak to znak, że baza jest zainicjalizowana.
Czy /onboard robi commit do gita?
Nie - kończy komunikatem „Not committed - your call”. Pierwszy commit robisz sam (albo zlecasz agentowi: „commit this”). Agent doda pliki i zrobi commit, pomijając .kb-onboard.json (jest pomijany przez gita).
Czy do onboardingu potrzebuję Pythona?
Tak - kreator używa skryptów pythonowych (render.py do wygenerowania plików schemy, build_indexes.py do indeksów), a Python jest też wymagany później przez /reindex i /lint. yt-dlp i ffmpeg są opcjonalne - przydają się dopiero przy /ingest z YouTube (lekcja 3).
Zostaw maila - dam znać, gdy ruszą gotowe paczki wiedzy.
Zapisz się na listę →