Pre-revenue startup without a finance department. AI agent system anatomy.

Today is May 9, 2026. Two days ago I gave a talk at NoCode Poland #4 - "How 2 founders do the work of a whole team". The title sounds like clickbait, but a week earlier, on May 1, part of what I was talking about didn't exist yet.
On May 1 at 200IQ LABS - the pre-revenue company I run with Przemek - there was no finance department. Zero April management report. Zero category-level cost control. Zero spec. On May 3 we did the first April close: 30+ classification rules trained from scratch, a management report in monthly/2026-04.md, and a real EBITDA of −16,804 PLN documented with three plan-correction decisions for the coming months.
Two days from zero to a working management system. Honestly - I did this partly for the talk. Event Driven Development™ (the event was the talk). But this system was overdue. I'd rather ship PRs to production than sit on numbers - that's the founder truth. The talk just forced the timing.
This article isn't about "AI replacing accountants". It won't - formal accounting via inFakt + an accountant handles compliance, and still does. This article is about how to architecturally build an AI agent system that genuinely replaces specialist roles in the management layer - where the department doesn't exist because the company is too small to hire and too big to improvise.
Three pillars I keep returning to throughout the text:
- Skills automate processes. Workflow becomes a noun - /finances close 2026-04 instead of 6 manual steps.
- Determinism through rules. Hybrid rules-first + LLM fallback + learning loop. The system converges from probabilistic to deterministic.
- Shared context. CLAUDE.md, MEMORY.md, the context/ structure. Without it, subagents are isolated chats. With it - a system that remembers the company.
Architecture: one diagram, three layers
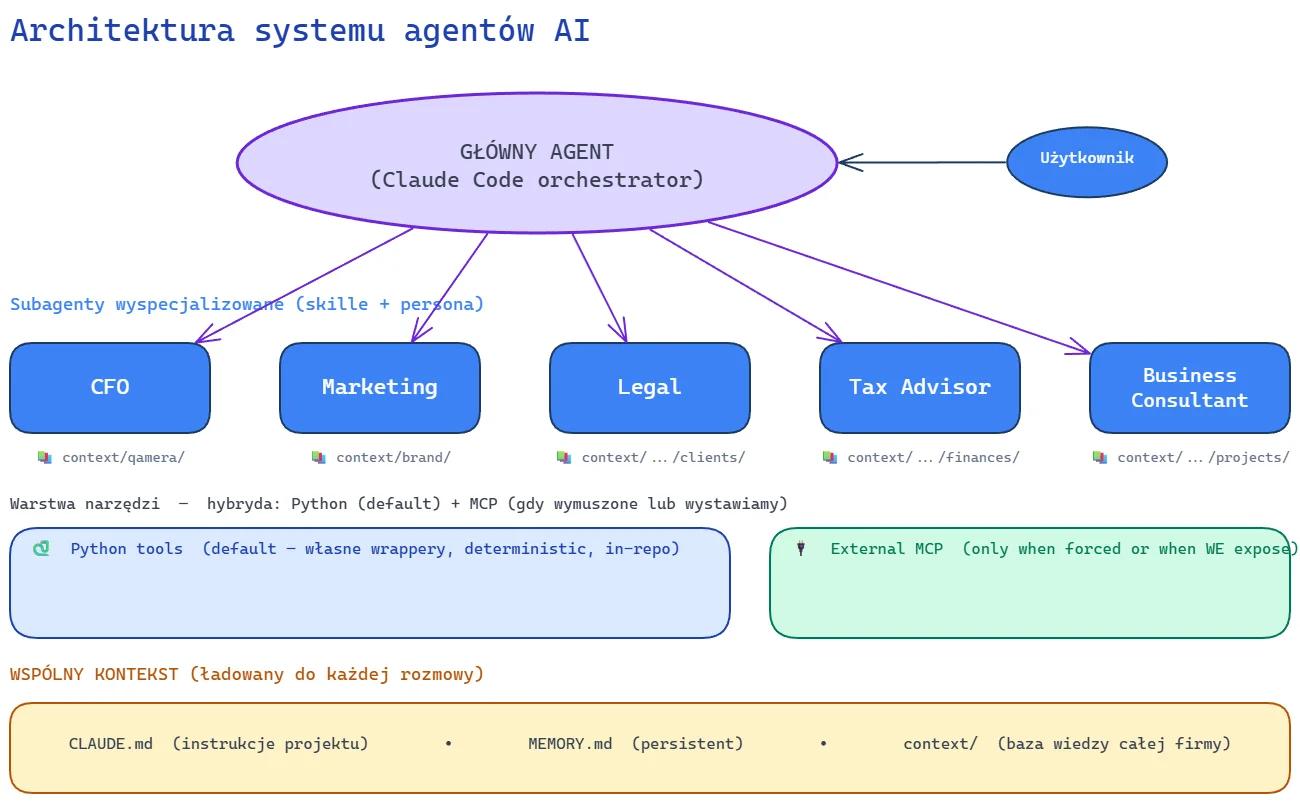
This diagram is the spine of the article. Each of the three layers maps to one of the pillars I'll come back to.
The main agent is Claude Code acting as an orchestrator. From its perspective I'm the user; it's the entry point. Routing to subagents happens through skills - I type /finances close 2026-04, the agent loads the finances skill, persona switches to CFO.
Specialized subagents - CFO, Marketing, Legal, Tax Advisor, Business Consultant - aren't separate processes or separate models. They're combinations of skill + persona + scoped context. CFO reads context/finances/, Marketing reads context/qamera/ (because Qamera is our product) and context/brand/, Legal reads context/legal-entities.md and context/company.md. Each role only sees what it needs - context hygiene.
The tools layer is a hybrid: Python (default for planned workflow) + External MCP (for ad-hoc or when an API forces it). Stripe, Revolut, Airtable are Python wrappers in the repo - because we know up-front how we use them. inFakt is MCP because the costs endpoint returns 403 when an accounting office handles the entity - the official MCP server bypasses that limitation. Qamera AI has its own MCP, used by both external agents and ourselves - because for ad-hoc exploration of our own product, MCP is just faster than writing a script per query.
Shared context is the substrate of the entire system. CLAUDE.md loads into every conversation - project instructions, conventions, paths. MEMORY.md is persistent across sessions. context/ is a structured knowledge base: finances, clients, projects, operations. Subagents read from this base - and that's why they aren't isolated chats.
Now in order.
Pillar 1: Skills automate processes
A skill is a unit that encloses a process - trigger, steps, decisions, integrations. Before skills, your workflow lives in your head and someone's notebook. With skills, the workflow becomes a noun: /finances close YYYY-MM, /ingest, /slides:new. Command instead of memory.
Sounds banal. It isn't. Without a skill I improvise every time: "hey, pull Stripe data for April, then Revolut, classify transactions, check accruals, write the report". That means I reinvent the same sequence 6 times a day. With /finances close 2026-04 - one command, deterministic phase sequence.
/finances close - 6 phases
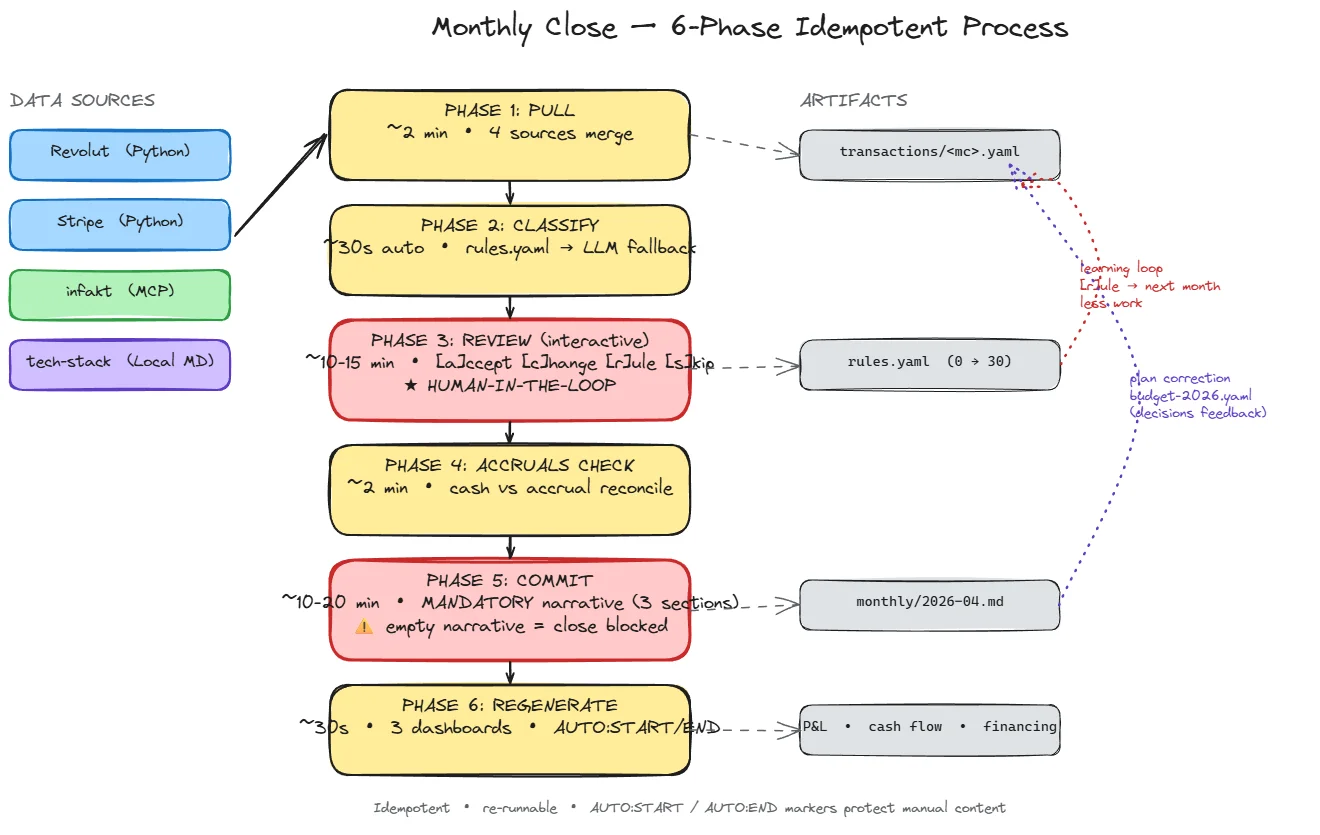
PHASE 1: PULL (~2 min) Revolut + Stripe (Python) + inFakt (MCP) + tech-stack
PHASE 2: CLASSIFY (~30s) rules.yaml deterministic → LLM fallback
PHASE 3: REVIEW (~10-15min interactive) [a/c/r/s] learning loop
PHASE 4: ACCRUALS CHECK (~2 min) accrued-liabilities.yaml matching
PHASE 5: COMMIT (~10-20 min) mandatory narrative blocks close
PHASE 6: REGENERATE (~30s) 3 dashboards, AUTO:START/END markers
Each phase is idempotent - restart after a crash doesn't duplicate data. You can run this close, interrupt after PHASE 3, come back an hour later, and continue from where you stopped. This isn't pipe-and-pray; it's a transactional operation in the sense of "you can repeat it and nothing bad happens".
Video: one close, live
Full April 2026 close run as /finances close 2026-04. ~7 minutes, 6 phases, 2 QA iterations stayed in the recording - meta-message: you can correct things by talking to the agent.
The recording keeps two QA iterations - moments where I stopped the agent, noticed something was off, and asked for a correction without restarting the whole phase. I deliberately didn't cut them out. That shows something that gets lost in marketing demos: a workflow with an agent isn't a single-pass script. You can correct via conversation, the agent adjusts state, continues.
Generalization: any process can be a skill
/finances close is the flagship skill, but the same mechanic works everywhere. /ingest classifies files dropped into inbox/ - I described it in detail in the PIT-38 case study. /slides:new generates a presentation skeleton. Meta-twist: the NCP4 slides I mention in the intro were created with the same workflow. The very /blog-article-writer skill used for this article has its own phases: prime → plan → execute → validate → translate.
Mandatory narrative blocks close
PHASE 5 requires that a human writes three narrative sections in monthly/<YYYY-MM>.md:
- What happened unexpectedly (vs plan).
- Decisions taken during the month.
- Plan for next month / plan correction.
Empty narrative blocks the close. The system won't close the month until you write something in each section.
This looks like pointless formalism - and from the "I just want to close fast" perspective, it is. But from the "six months later I'm staring at EBITDA variance −3,160 vs plan and don't know why" perspective, it's the only way decisions retain durable memory.
Reflection is part of the process, not optional.
This pattern is broader than finances: every time you automate something where value lies in understanding rather than execution - add a human-in-the-loop checkpoint that can't be skipped. Otherwise you'll automate execution and destroy understanding.
Pillar 2: Determinism through rules
Transaction classification is a classic cold-start problem. Pure rules: every new vendor needs manual setup, a month with no new vendors is a good week, a month with 5 new ones is an evening. Pure LLM: non-deterministic, cheap at scale, but unacceptable in finance - audit, regulator, future inspection.
The third path is hybrid: rules-first + LLM fallback + learning loop.
Rules-first
# rules.yaml - fragment
- id: gworkspace-via-gcp
pattern:
memo: "GCPLD"
source: infakt
amount_range: [200, 500]
classify:
category: opex/saas
unit: null
note: "Google Workspace billowane przez Google Cloud Poland (300-330 PLN/mc)"
created_at: 2026-05-04
- id: gcp-infakt
pattern:
memo: "GCPLD"
source: infakt
amount_range: [500, 999999]
classify:
category: cogs/ai-generation
unit: qamera
note: "Faktury GCP w inFakt z prefiksem GCPLD i kwotą >500 PLN = compute"
created_at: 2026-05-04
The strongest detail: two rules for the same vendor (GCPLD in inFakt), differing only in amount_range. 200-500 PLN → Google Workspace (category opex/saas). >500 PLN → compute GCP for the Qamera pipeline (category cogs/ai-generation).
This is the type of nuance an LLM gets differently every time. One day it classifies all GCPLD as Workspace, the next as compute, the third randomly. Here we have the answer encoded as code. Auditable, deterministic, idempotent.
The note: field matters as much as the pattern. Without that note, six months later I look at the rule and don't know why splitting by amount_range makes sense. A rule without a note is long-term debt.
LLM fallback with few-shot examples
When no rule matches, the agent falls back to LLM with a few-shot prompt. Each example in examples.yaml has explicit reasoning:
# examples.yaml - fragment
- transaction:
date: 2026-04-10
amount: -127.40
memo: "BYTEPLUS API USAGE PAY-AS-YOU-GO"
source: revolut
classification:
category: cogs/ai-generation
unit: qamera
reasoning: "Byteplus to provider Kling AI używany do generacji video w produkcie"
The LLM gets 15-25 such examples per category. It returns a classification plus its own reasoning. The reasoning is visible to the user in the REVIEW phase - it's not a black box. I see not just "category X" but why.
Learning loop: REVIEW [a]ccept / [c]hange / [r]ule / [s]kip
A loop per LLM-classified transaction. Four decisions:
| Option | What it does |
|---|---|
| [a]ccept | LLM was right, but it's a one-off case |
| [c]hange | LLM got it wrong, manual correction |
| [r]ule | Accept + create a rule for similar cases |
| [s]kip | Don't know, we'll come back next close |
Golden rule: if the transaction is likely to repeat → [r]ule. 30 seconds now, you save minutes over the coming months. Every [r]ule freezes the LLM's guess into a deterministic rule in rules.yaml. Next close - the same transaction lands in "auto-classified" deterministically.
Real number: the first close (April 2026) generated 30+ rules from zero. Three pattern types surfaced immediately:
- By memo - pure pattern matching. Byteplus, Cursor, Meta Pay.
- By inFakt invoice prefix + amount - GCPLD with amount_range: [200, 500] is Workspace, with [500, ∞] is compute. Same vendor, two categories.
- By reseller pattern - Paddle 24 EUR ≈ 100 PLN is n8n cloud. But Paddle with a different amount = REVIEW (could be a different product sold via Paddle).
The system converges from probabilistic to deterministic. This is a rare design - most budget classification tools are either 100% deterministic (rigid rules, lots of manual work) or 100% probabilistic (LLM/ML, no audit). The hybrid with [r]ule as a bridge between the two gives you LLM cold-start and long-term audit of deterministic rules.
Idempotent regeneration as an orthogonal determinism mechanism
The second layer of determinism is the dashboards. PHASE 6 regenerates 3 files: _dashboard.md, _alerts.md, _runway.md. Question: what about manual notes I added during the month? If regeneration overwrites the whole file - my notes vanish and I stop writing notes.
Solution: scope markers.
# 200IQ LABS - Finances Dashboard
<!-- AUTO:START -->
## Cash position & runway
| Metric | Value |
|---|---|
| Cumulative shareholder loans | 74,300 PLN |
| Confirmed financing (June) | +100,000 PLN |
| Accrued liabilities (UoD payout May) | −24,000 PLN |
| Run-rate burn | ~14-14.5k PLN/mo |
<!-- AUTO:END -->
## Manual notes (outside markers - survive regeneration)
- 2026-05-04: first system close. Manual dashboard regeneration.
- Plan finalize: not done - `draft` mode kept deliberately until next close.
The AUTO:START / AUTO:END markers limit the scope of regeneration. Everything outside the markers survives every regeneration. Without it, nobody writes manual notes in auto-generated documents - and those documents become dead. This simple pattern decides whether dashboards get used or ignored.
Pillar 3: Shared context (the substrate)
The third pillar is the layer that makes all subagents coherent. Without shared context, CFO and Marketing don't know about each other - you have 5 isolated chats, each with its own version of truth. With shared context, you have a system that remembers the company.
Three layers of shared context
- CLAUDE.md (per-project) - instructions, conventions, paths, "what should the agent do when in doubt". Loads into every conversation.
- MEMORY.md (cross-conversation) - auto-memory, persistent across sessions. This is where "the user prefers short summaries", "project X uses OpenSpec", "today's date is YYYY-MM-DD" live.
- context/ (knowledge base) - a structured base per domain. context/finances/, context/qamera/, context/clients/, context/operations/.
Directory layout (simplified):
agentic-ai-system/
├── CLAUDE.md # project instructions
├── memory/
│ └── MEMORY.md # auto-memory, persistent
├── context/
│ ├── finances/ # ← read by skill CFO
│ ├── qamera/ # ← read by skill Marketing (revenue + brand)
│ ├── clients/ # ← read by skill Business Consultant
│ └── operations/
├── skills/
│ ├── finances/SKILL.md
│ ├── ingest/SKILL.md
│ └── slides/SKILL.md
└── tools/
├── stripe/ # Python wrappers
├── revolut/ # Python wrappers
└── airtable/ # Python wrappers
Each subagent has a scope - it doesn't read everything. CFO reaches into context/finances/ and context/operations/, with read-only access to context/qamera/ for revenue. It doesn't read context/clients/ (that's the Business Consultant's scope) because it doesn't need to. Context hygiene is the second multiplier of value - without it, every CFO question pulls half the company into tokens.
Python tools (default) vs External MCP (when forced)
Rule: Python script for planned workflow. MCP for ad-hoc or when the API forces it.
| Integration | Approach | Why |
|---|---|---|
| Stripe (Qamera subscriptions) | Python | We know up-front what we need - wrapper is part of the spec |
| Revolut (company transactions) | Python | Fixed sequence in /finances close, own wrapper |
| Airtable (CRM) | Python | Repeatable CRM operations, own wrapper |
| inFakt (accounting) | MCP | Costs endpoint returns 403 when an accounting office handles the entity - MCP forced |
| Qamera AI (our product) | MCP | Both us and external agents. REST API is also available, but for ad-hoc exploration MCP is just faster to wire up |
Why Python > MCP, when the workflow is planned:
- Token economy. MCP loads tool descriptions into the context of every conversation. Script = zero overhead. The script is invoked only when the agent decides it's needed.
- Determinism. A script does exactly what it says. No "the model interpreted the tool differently in another conversation".
- Trivial to create. "Agent, I need a script that pulls all active Stripe subscriptions on day X" → agent generates, I code-review, commit. 15 minutes.
- Full control. Code in the repo, versioned, readable for another developer. I can debug in Python, add logging, change output format - without negotiating with the MCP protocol.
Why MCP, when we use it ad-hoc:
If I'm still discovering how I'll use something - writing a script is premature. I don't know yet which fields I care about, which filters, what output format. MCP gives the agent immediate access to the API; after several iterations I see the pattern worth freezing - and then I write the script. The script is part of the workflow specification; MCP is a tool for exploration.
That's exactly how we use Qamera: external agents hit the MCP, we do too - when we want to quickly check something in our own product. If we had a steady workflow like "generate X for client Y every week" - we'd write a script. Right now we don't, so MCP suffices.
With inFakt we have no choice - the REST API returns 403 on the costs endpoint when an accounting office handles the entity. Here MCP isn't an architectural choice, just the only available path to data.
Subagents read only their scope
Back to the first diagram: each subagent (skill + persona) has a scope on its context line. The finances skill has front-matter that explicitly declares:
context_scope:
- context/finances/
- context/operations/
- context/qamera/ # read-only, for subscription revenue
Without this restriction, the agent asks "what were the transactions in March" and pulls the whole company's context into tokens. With the restriction - it only loads context/finances/transactions/2026-03.yaml plus rules. Fewer tokens, faster response, lower hallucination risk.
I wrote about the same pattern in a different context - the inbox/ / archive/ / data/ separation in the PIT-38 case study. The pattern generalizes: the agent works on clean, processed files, not raw data.
Case study: real numbers from April 2026
Proof that this isn't a demo. The first close, executed on 2026-05-04, generated:
| Line | Actual | Plan | Δ |
|---|---|---|---|
| Revenue | 347 PLN | 598 PLN | −42% |
| Costs | 17,151 PLN | 14,242 PLN | +20% |
| EBITDA | −16,804 PLN | −13,644 PLN | −23% |
| cogs/ai-generation | 1,709 | 700 | +144% 🔴 |
| opex/marketing | 2,996 | 1,500 | +100% 🔴 |
| opex/saas | 2,112 | 1,633 | +29% 🟡 |
Three decisions arising from the close (recorded in monthly/2026-04.md):
- GCP +144% vs plan → the plan was wrong (700 PLN), the real run-rate is historically 1,000-1,600 PLN/mo. Plan May-Dec raised retroactively to 1,500-1,800 PLN. Conscious decision NOT to optimize GCP - part of this is content marketing (own + materials for clients). The "this is actually marketing" classification doesn't change the category (GCP stays in cogs/ai-generation), but it justifies a higher plan.
- Cursor billed 4×/mo (716 PLN vs plan 217) → planned Cursor → Claude migration (rigid ~90 EUR/mo cap, predictable cost instead of usage-based).
- Meta Ads off from May - strategy was wrong, direction TBD. Control plan: in the May close we'll verify spend < 300 PLN.
The point: the decisions follow from the system, but the system doesn't make them. The system shows variance and requires a narrative in PHASE 5. The decision is mine - but I have it documented for the moment six months later when I forget why.
Break-even target: September 2026 (revenue 12,184 vs costs 12,842, EBITDA −658). Aggressive plan - needs validation in upcoming closes. Plan = a living document, corrected after every close as run-rate shifts. Drift > 30% = revision required.
What I don't recommend
A risk map, mirroring the section from the PIT-38 case study.
- I don't recommend this setup for someone without programming comfort. Markdown, YAML, git, terminal, editing convention files - requires fluency with tools. Without it, the time lost on setup eats all the gains. Safer path: a ready-made controlling SaaS (Causal, Runway, Pry) + Excel + an accountant.
- Manual first, automate after pain. The first 2-3 closes MUST be manual. Without a manual run, half the rules would be designed wrong. The first close revealed 30+ patterns to encode - including non-obvious ones (e.g. that GCPLD is two categories, not one). Scripts come after, not before.
- A management system ≠ formal accounting. inFakt + an accountant do compliance. This system makes decisions. Don't substitute one for the other - they complement, not replace. I still pay my accountant a monthly retainer; this system doesn't remove that line from the budget.
- LLMs make arithmetic errors. Send sums to a compute engine (Excel, calculator, MF system). LLMs add value in structure and interpretation, not arithmetic. I wrote about this in the PIT-38 case study - I left 6 cents on the table because the LLM tripped subtracting two six-digit numbers.
- It doesn't scale linearly beyond one company. The system is designed for 200IQ LABS. The patterns generalize (skills, rules, context); the specific YAMLs don't. "Don't copy the setup, extract the principles" - that was the motto of the NCP4 talk and it's the motto of this article.
Key takeaways
- Skills make a process a noun. /finances close YYYY-MM instead of 6 manual steps. Every repeatable workflow deserves its own skill - with phases, idempotency, and mandatory checkpoints where value lies in understanding.
- Determinism is built iteratively. Rules-first + LLM fallback + the [r]ule option in REVIEW = the system converges from probabilistic to deterministic. After the first close we had 30+ rules. After the tenth we'll have ~150, with the LLM invoked rarely.
- Shared context (CLAUDE.md, MEMORY.md, context/) is substrate, not decoration. Without it, subagents are isolated chats. With it - a system that remembers the company and shares knowledge across roles.
- Python script for planned workflow, MCP for ad-hoc. A script is part of the spec - token-efficient, deterministic, code-reviewable. MCP gives immediate access when you don't yet know how you'll use something, or when the API forces it.
- Reflection is part of the process, not optional. Mandatory narrative blocks close. Without it, six months later you don't know why something was.
I'd rather ship code than count beans - and the agents help me with both. This system was overdue. The driving event was the talk. It works.
Running a pre-revenue startup and thinking about an AI management system?
I help founders and technical consultants design AI agent architectures for company operations - skills, deterministic rules, shared context. I'll show you what such a setup could look like for you.
Book a free consultationUseful Resources
- Claude Code - documentation - reference for skills, settings, MCP, hooks
- Model Context Protocol - spec - what MCP is and when it makes sense
- PIT-38 case study - the same architectural pattern in a tax-filing context
- Skills 2.0 - multi-agent system for company management - broader Skills 2.0 context and the role of subagents
- OpenSpec workflow - structured AI work - spec-driven development as the foundation for skills
- Spec-driven SEO on the portfolio and Qamera AI - another case study, the same type of workflow
FAQ
Does this pattern (skills + rules + shared context) work only in Claude Code, or in other agents too?
The pattern is agent-agnostic. Skills map to commands/functions in other systems (Cursor commands, n8n workflows, custom CLIs). Rules + few-shot examples are a standard ML technique. Shared context (markdown + directory structure) works anywhere the agent has file access. The specific mechanisms (CLAUDE.md, MCP, MEMORY.md) are Anthropic-specific, but the architectural principles generalize to any LLM-driven system.
How long does it take to build a system like this from scratch?
The first working close - with OpenSpec, YAML schemas, and 30+ rules - took us two days of intensive two-person work. Full stabilization (auto-pull scripts, scheduled close, integration with formal accounting) is planned over 4-6 weeks at a regular monthly cadence. Every day you use a manually designed skill is a productive day - you're not waiting for the system to be complete, because value shows up immediately after the first close.
Why a Python script instead of MCP, if MCP is the standard?
MCP loads tool descriptions into the context of every conversation - that's a token cost and a potential interpretation ambiguity across sessions. A Python script is zero overhead, deterministic output, code in the repo for code-review. We write scripts for planned workflow (Stripe, Revolut, Airtable - we know up-front what we need, so the script is part of the spec). We use MCP for ad-hoc (exploring our own Qamera, when we don't yet know which queries will repeat) or when the API forces it (inFakt returns 403 on the costs endpoint when an accounting office handles the entity). Pattern: after several ad-hoc iterations, you can see what's worth freezing into a script.
Won't the LLM make mistakes in financial classification? What about audit for the regulator?
We design the hybrid (rules-first + LLM fallback) specifically to minimize LLM-classified transactions. Every LLM-classified transaction goes through REVIEW - a human sees the reasoning and decides [a]ccept/[c]hange/[r]ule/[s]kip. After the first close we had 30+ rules that deterministically catch 80%+ of subsequent transactions. The audit trail lives in rules.yaml plus monthly/<YYYY-MM>.md - every decision documented, every rule has a note: with justification. Formal accounting (compliance) still goes through inFakt + an accountant; this system is managerial, not compliance.
What does mandatory narrative do if I have an emergency close and don't have time to write 3 sections?
The three sections (surprises / decisions / plan correction) block the close until filled - that's a deliberate decision. In an extreme case you can write a single sentence in each section ("no surprises vs plan", "no decisions", "continuing without corrections"). The system doesn't grade narrative quality, only its presence. The point is that six months later, looking at EBITDA variance, you need any context - short is better than none. This formalism is intentional.
Does this system work for a revenue-stage company, not just pre-revenue?
Yes, the pattern scales - P&L categories and caps need adjusting, mandatory narrative becomes even more important (more transactions = more decisions to document), the learning loop yields better ROI (more repeating vendors). But in a post-revenue company with high volume you probably need a full ERP - a management system in markdown and YAML hits a ceiling at ~hundreds of transactions/month and a few decision-makers. Our scope: pre-revenue → early-revenue, 1-5 people in the company. Above that scale the architecture needs harder tools.